Експерименти в науці та промисловості
Експериментальні методи широко використовуються в дослідженнях, а також у промислових умовах, однак іноді для зовсім інших цілей. Основна мета наукового дослідження зазвичай полягає в тому, щоб показати статистичну значущість впливу, який певний фактор справляє на залежну змінну, що цікавить (докладніше про концепцію статистичної значущості див . у розділі Основні поняття ).
У промислових умовах основною метою зазвичай є отримання максимальної кількості неупередженої інформації щодо факторів, що впливають на виробничий процес, із якомога меншої кількості (коштовних) спостережень. У той час як у першому застосуванні (в науці) методи дисперсійного аналізу ( ANOVA ) використовуються для розкриття інтерактивної природи реальності, яка проявляється у взаємодії факторів вищого порядку, у індустрії «незручність» (вони часто не становлять інтересу; вони тільки ускладнюють процес виявлення важливих факторів).
Відмінності в техніках
Ці відмінності в цілях мають глибокий вплив на методи, які використовуються в двох налаштуваннях. Якщо ви переглянете стандартний текст ANOVA для науки, наприклад, класичні тексти Вінера (1962) або Кеппела (1982), ви виявите, що вони в основному обговорюватимуть дизайни з, можливо, п’ятьма факторами (проекти з більш ніж шістьма факторами). фактори зазвичай непрактичні; див. Вступний огляд до ANOVA/MANOVA ). Ці дискусії зосереджені на тому, як отримати дійсні та надійні тести статистичної значущості. Однак, якщо ви переглянете стандартні тексти про експерименти в промисловості (Box, Hunter і Hunter, 1978; Box and Draper, 1987; Mason, Gunst і Hess, 1989; Taguchi, 1987), ви побачите, що вони в основному обговорюватимуть проекти з багато факторів (наприклад, 16 або 32), у яких ефекти взаємодії не можуть бути оцінені, і основний фокус обговорення полягає в тому, як отримати неупереджені оцінки основного ефекту (і, можливо, двосторонньої взаємодії) за допомогою мінімальної кількості спостережень.
Це порівняння можна розширити далі, однак тепер буде обговорено більш детальний опис експериментального дизайну в промисловості та стануть зрозумілими інші відмінності. Зауважте, що довідка ANOVA/MANOVA містить детальні обговорення типових проблем дизайну в наукових дослідженнях, а процедура ANOVA/MANOVA є дуже повною реалізацією підходу загальної лінійної моделі до ANOVA/MANOVA (однофакторного та багатофакторного ANOVA). Звичайно, є застосування в промисловості, де загальний дизайн ANOVA, який використовується в наукових дослідженнях, може бути надзвичайно корисним. Ви можете прочитати розділ « Вступний огляд » до ANOVA/MANOVAГоловне отримати більш загальну оцінку діапазону методів, охоплених терміном Експериментальний план .
Огляд
Загальні ідеї та принципи, на яких базується експериментування в промисловості, а також типи використовуваних конструкцій будуть обговорюватися в наступних параграфах. Наступні параграфи є вступними. Однак передбачається, що ви знайомі з основними ідеями дисперсійного аналізу та інтерпретації основних ефектів і взаємодій у ANOVA. В іншому випадку наполегливо рекомендуємо прочитати розділ « Вступний огляд » для ANOVA/MANOVA .
Загальні ідеї
Загалом, кожна машина, яка використовується у виробничому процесі, дозволяє своїм операторам регулювати різні налаштування, що впливає на кінцеву якість продукту, виготовленого машиною. Експериментування дозволяє інженеру-виробничнику систематично регулювати параметри машини та дізнаватися, які фактори мають найбільший вплив на кінцеву якість. Використовуючи цю інформацію, параметри можна постійно вдосконалювати до досягнення оптимальної якості. Щоб проілюструвати це міркування, ось кілька прикладів:
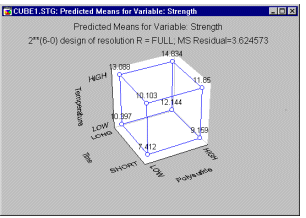
Приклад 1: Виробництво барвників. Бокс і Дрейпер (1987, сторінка 115) повідомляють про експеримент, пов'язаний з виготовленням певних барвників. Якість у цьому контексті можна описати в термінах бажаного (вказаного) відтінку та яскравості та максимальної міцності тканини. Крім того, важливо знати, що змінити, щоб отримати інший відтінок і яскравість, якщо смак споживачів зміниться. Іншими словами, експериментатор хотів би визначити фактори, що впливають на яскравість, відтінок і силу кінцевого продукту. У прикладі, описаному Боксом і Дрейпером, існує 6 різних факторів, які оцінюються за схемою 2**(6-0) ( 2**(kp)позначення пояснюються нижче). Результати експерименту показують, що трьома найважливішими факторами, що визначають міцність тканини, є полісульфідний індекс, час і температура (див. Box and Draper, 1987, стор. 116). Можна узагальнити очікуваний ефект (передбачувані середні значення) для змінної, що цікавить (тобто міцність тканини в даному випадку) у так званому кубі. Цей графік показує очікувану (прогнозовану) середню міцність тканини для відповідних низьких і високих параметрів для кожної з трьох змінних (факторів).
Приклад 1.1: Конструкції скринінгу. У попередньому прикладі одночасно оцінювалися 6 різних факторів. Нерідко існує дуже багато (наприклад, 100) різних факторів, які потенційно можуть бути важливими. Спеціальні плани (наприклад, плани Плакетта-Бермана, див. Plackett and Burman, 1946) були розроблені для ефективного скринінгу такої великої кількості факторів, тобто з найменшою кількістю необхідних спостережень. Наприклад, ви можете розробити та проаналізувати експеримент із 127 факторами та лише 128 прогонами (спостереженнями); тим не менш, ви зможете оцінити основні ефекти для кожного фактора, і, таким чином, ви можете швидко визначити, які з них є важливими та, швидше за все, приведуть до покращення в досліджуваному процесі.
Приклад 2: дизайн 3**3. Монтгомері (1976, сторінка 204) описує експеримент, проведений з метою виявлення факторів, які сприяють втраті сиропу безалкогольного напою через спінювання під час наповнення п’ятигалонних металевих контейнерів. Враховувалися три фактори: (а) конфігурація сопла, (б) оператор машини та (в) робочий тиск. Кожен фактор було встановлено на трьох різних рівнях, що призвело до повної схеми експерименту 3**(3-0) (позначення 3**(kp) пояснюється нижче).
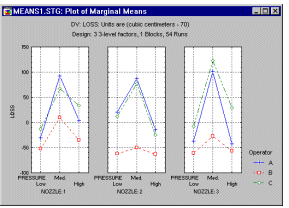
Крім того, було зроблено два вимірювання для кожної комбінації налаштувань фактора, тобто схема 3**(3-0) була повністю відтворена один раз.
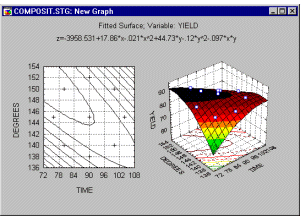
Приклад 3: максимізація виходу хімічної реакції. Вихід багатьох хімічних реакцій є функцією часу та температури. На жаль, ці дві змінні часто не впливають на підсумкову врожайність лінійним чином. Іншими словами, це не так, що «чим довший час, тим більший урожай», а «чим вища температура, тим більший урожай». Натомість обидві ці змінні зазвичай криволінійно пов’язані з результуючою врожайністю.
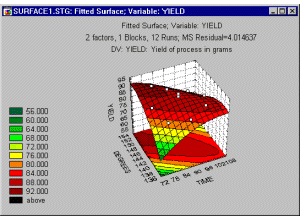
Таким чином, у цьому прикладі вашою метою як експериментатора буде оптимізація поверхні текучості , яка створюється двома змінними: часом і температурою .
Приклад 4: Перевірка ефективності чотирьох присадок до палива. Схеми латинського квадрата корисні, коли фактори, що цікавлять, вимірюються на більш ніж двох рівнях, і природа проблеми передбачає певне блокування. Наприклад, уявіть собі дослідження 4 паливних добавок щодо зменшення оксидів азоту (див. Box, Hunter і Hunter, 1978, стор. 263). У вашому розпорядженні може бути 4 водія і 4 машини. Вас особливо не цікавить будь-який вплив конкретних автомобілів або водіїв на кінцеве відновлення оксиду; однак ви не хочете, щоб результати для присадок до палива були упередженими для конкретного водія чи автомобіля. Проекти латинського квадрата дозволяють неупереджено оцінити основні ефекти всіх факторів дизайну. Що стосується прикладу, розташування рівнів обробки у формі латинського квадрата гарантує, що мінливість серед водіїв або автомобілів не впливає на оцінку ефекту через різні присадки до палива.
Приклад 5: Покращення однорідності поверхні при виготовленні полікремнієвих пластин. Виробництво надійних мікропроцесорів вимагає дуже високої узгодженості виробничого процесу. Зверніть увагу, що в цьому випадку так само, якщо не важливіше, контролювати мінливістьпевних характеристик продукту, ніж контроль середнього значення для характеристики. Наприклад, щодо середньої товщини поверхні шару полікремнію процес виробництва може бути повністю контрольованим; однак, якщо мінливість товщини поверхні на пластині коливається в широких межах, отримані мікрочіпи не будуть надійними. Фадке (1989) описує, як різні характеристики виробничого процесу (такі як температура осадження, тиск осадження, потік азоту тощо) впливають на змінність товщини поверхні полікремнію на пластинах. Однак не існує теоретичної моделі, яка дозволила б інженеру передбачитияк ці фактори впливають на однорідність вафель. Тому для оптимізації процесу потрібне систематичне експериментування з факторами. Це типовий приклад застосування надійних методів проектування Тагучі .
Приклад 6: Конструкції сумішей. Корнелл (1990, стор. 9) наводить приклад типової (простої) проблеми суміші. Зокрема, було проведено дослідження для визначення оптимальної консистенції рибних котлет на основі відносних пропорцій різних видів риби (кефалі, вівчарини та горбаля), які складали котлети. На відміну від експериментів без змішування, загальна сума пропорцій повинна дорівнювати константі, наприклад, 100%. Результати таких експериментів зазвичай графічно зображують у вигляді так званих трикутних (або трикутних) графіків.
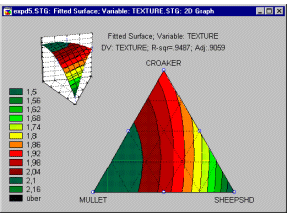
Загалом, загальне обмеження — сума трьох компонентів має бути константою — відображається на трикутній формі графіка (див. вище).
Приклад 6.1: Обмежені конструкції сумішей. У конструкціях сумішей особливо часто відносні кількості компонентів додатково обмежуються (на додаток до обмеження, що їх сума повинна становити, наприклад, 100%). Наприклад, припустімо, що ми хочемо розробити фруктовий пунш із найкращим смакомщо складається із суміші соків п'яти фруктів. Оскільки отримана суміш має бути фруктовим пуншем, чисті суміші, що складаються з чистого соку лише одного фрукта, обов’язково виключаються. Додаткові обмеження можуть бути накладені на «всесвіт» сумішей через обмеження вартості або інші міркування, так що один окремий фрукт не може, наприклад, становити більше 30% сумішей (інакше фруктовий пунш буде занадто дорогим, термін придатності був би скомпрометований, пунш не міг бути виготовлений у достатньо великих кількостях тощо). Такі так звані обмежені експериментальні області представляють численні проблеми, які, однак, можна вирішити.
Загалом, за таких умов намагаються розробити експеримент, який потенційно може отримати максимальну кількість інформації про відповідну функцію відповіді (наприклад, смак фруктового пуншу) в експериментальній області, що цікавить.
Обчислювальні задачі
В основному є два загальні питання, які розглядаються в експериментальному плані:
Компоненти дисперсії, синтез знаменника
Існує кілька статистичних методів для аналізу дизайнів із випадковими ефектами (див. Методи дисперсійного аналізу ). У розділі « Компоненти дисперсії та змішана модель ANOVA/ANCOVA» обговорюються численні варіанти оцінки компонентів дисперсії для випадкових ефектів , а також для виконання приблизних F - тестів на основі синтезованих термінів помилки.
Резюме
Експериментальні методи знаходять все більше застосування у виробництві для оптимізації виробничого процесу. Зокрема, метою цих методів є визначення оптимальних параметрів для різних факторів, що впливають на виробничий процес. У ході обговорення до цього часу були введені основні класи планів, які зазвичай використовуються в промислових експериментах: 2**(kp) (дворівневі, багатофакторні) дизайни, проекти скринінгу для великої кількості факторів, 3** (kp) (трирівневі, багатофакторні) схеми (також підтримуються змішані схеми з 2 і 3 факторами рівня), центральні композитні схеми (або поверхні відгуку) , схеми латинського квадрата , надійний аналіз конструкції Тагучі , сумішдизайни та спеціальні процедури для побудови експериментів у обмежених експериментальних областях. Цікаво, що багато з цих експериментальних методів «пройшли» від виробничого підприємства до управління, і повідомлялося про успішне впровадження в плануванні прибутку в бізнесі, оптимізації грошових потоків у банківській справі тощо (наприклад, див. Yokyama and Taguchi, 1975). ).
Тепер ці методи будуть описані більш детально в наступних розділах:
У багатьох випадках достатньо розглянути фактори, що впливають на виробничий процес, на двох рівнях. Наприклад, температура для хімічного процесу може бути встановлена трохи вище або трохи нижче, кількість розчинника в процесі виробництва барвника може бути або трохи збільшена, або зменшена тощо. Експериментатор хотів би визначити, чи будь-який із цих параметрів зміни впливають на результати виробничого процесу. Найбільш інтуїтивно зрозумілим підходом до вивчення цих факторів було б варіювати фактори, що цікавлять, у повному факторному плані, тобто спробувати всі можливі комбінації налаштувань. Це буде нормально, за винятком того, що кількість необхідних прогонів в експерименті (спостережень) збільшиться геометрично. Наприклад, якщо ви хочете вивчити 7 факторів, необхідна кількість прогонів в експерименті буде 2**7 = 128. Щоб вивчити 10 факторів, вам знадобиться 2**10 = 1024 експерименту. Оскільки для кожного циклу може знадобитися трудомістке та дороге налаштування та переналаштування обладнання, часто неможливо вимагати стільки різних виробничих циклів для експерименту. У цих умовах,використовуються дробові факторіали , які «жертвують» ефектами взаємодії, щоб основні ефекти все ще можна було обчислити правильно.
Створення дизайну
Технічний опис того, як будуються дробові факторні схеми, виходить за рамки цього вступу. Докладні відомості про те, як розробити експерименти 2**(kp), можна знайти, наприклад, у Bayne and Rubin (1986), Box and Draper (1987), Box, Hunter, and Hunter (1978), Montgomery (1991), Деніел (1976), Демінг і Морган (1993), Мейсон, Ганст і Гесс (1989) або Райан (1989) — це лише деякі з багатьох підручників на цю тему. Загалом, він буде послідовно «використовувати» взаємодії найвищого порядку для створення нових факторів. Наприклад, розглянемо наступний план, який включає 11 факторів, але вимагає лише 16 прогонів (спостережень).
| Дизайн: 2**(11-7), резолюція III | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| бігти | А | Б | C | Д | E | Ф | Г | Х | я | Дж | К |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 |
1 1 1 1 -1 -1 -1 -1 1 1 1 1 -1 -1 -1 -1 |
1 1 -1 -1 1 1 -1 -1 1 1 -1 -1 1 1 -1 -1 |
1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 |
1 1 -1 -1 -1 -1 1 1 -1 -1 1 1 1 1 -1 -1 |
1 -1 -1 1 -1 1 1 -1 1 -1 -1 1 -1 1 1 -1 |
1 -1 -1 1 1 -1 -1 1 -1 1 1 -1 -1 1 1 -1 |
1 -1 1 -1 -1 1 -1 1 -1 1 -1 1 1 -1 1 -1 |
1 -1 -1 1 -1 1 1 -1 -1 1 1 -1 1 -1 -1 1 |
1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 1 1 1 1 |
1 1 -1 -1 1 1 -1 -1 -1 -1 1 1 -1 -1 1 1 |
Читання дизайну. Наведений вище дизайн слід інтерпретувати наступним чином. Кожен стовпець містить +1 або -1, щоб вказати налаштування відповідного коефіцієнта (високий або низький відповідно). Так, наприклад, під час першого запуску експерименту встановіть для всіх факторів від A до K значення плюс (наприклад, трохи вище, ніж раніше); у другому циклі встановіть для факторів A, B і C позитивне значення, для фактора D — негативне значення тощо. Зауважте, що існує багато варіантів для відображення (та збереження) дизайну з використанням позначення, відмінного від �1 , для позначення параметрів факторів. Наприклад, ви можете використовувати фактичні значення факторів (наприклад, 90 градусівЦельсія та 100 градусів Цельсія) або текстові написи ( Низька температура, Висока температура).
Рандомізація прогонів. Оскільки багато інших речей можуть змінюватися від виробничого циклу до виробничого циклу, завжди доцільно визначати випадковий порядок, у якому виконуються систематичні запуску проектів.
Концепція проектної резолюції
Дизайн вище описаний як дизайн 2**(11-7) роздільної здатності III (три). Це означає, що ви вивчаєте загалом k = 11 факторів (перше число в дужках); однак p = 7 із цих факторів (друге число в дужках) були створені в результаті взаємодії повного факторного плану 2**[(11-7) = 4]. Як наслідок, дизайн не забезпечує повної роздільної здатності ; тобто існують певні ефекти взаємодії, які змішуються з (ідентичними) іншим ефектам. Загалом, схема роздільної здатності R є такою, де жодна l - стороння взаємодія не змішується з будь-якою іншою взаємодією порядку меншого за Rl. У поточному прикладі R дорівнює 3. Тут жодна взаємодія рівня l = 1 (тобто основні ефекти) не змішується з будь-якою іншою взаємодією порядку меншого за Rl = 3-1 = 2. Таким чином, основні ефекти в цій конструкції плутаються з двосторонніми взаємодіями; і, отже, всі взаємодії вищого порядку однаково змішані. Якби ви включили 64 прогони та згенерували схему 2**(11-5), результуюча роздільна здатність була б R = IV (чотири). Ви могли б зробити висновок, що жодна l = одностороння взаємодія (основний ефект) не плутається з будь-якою іншою взаємодією порядку меншого за Rl= 4-1 = 3. Отже, у цій конструкції основні ефекти не змішуються з двосторонньою взаємодією, а лише з тристоронньою взаємодією. А як щодо двосторонніх взаємодій? Жодна l = двостороння взаємодія не змішується з будь-якою іншою взаємодією порядку меншого, ніж Rl = 4-2 = 2. Таким чином, двосторонні взаємодії в цьому дизайні змішуються одна з одною.
Плани Плакетта-Бермана (матриця Адамара) для скринінгу
Коли необхідно відібрати велику кількість факторів, щоб визначити ті, які можуть бути важливими (тобто ті, які пов’язані із залежною змінною, що цікавить), потрібно застосувати схему, яка дозволяє перевірити найбільшу кількість основних факторів. ефектів з найменшою кількістю спостережень, тобто побудувати проект роздільної здатності III з якомога меншою кількістю прогонів. Один із способів розробити такі експерименти — змішати всі взаємодії з «новими» основними ефектами. Такі конструкції ще іноді називають насиченимиплани, оскільки вся інформація в цих планах використовується для оцінки параметрів, не залишаючи ступенів свободи для оцінки терміну помилки для ANOVA. Оскільки додані фактори створюються шляхом прирівнювання (накладення псевдонімів, див. нижче), «нових» факторів із взаємодією повного факторного плану, ці плани завжди матимуть 2**k циклів (наприклад, 4, 8, 16, 32, і так далі). Плакетт і Берман (1946) показали, як повний факторний план можна фракціонувати іншим способом, щоб отримати насичені плани, де кількість прогонів кратна 4, а не степеню 2. Ці плани також іноді називають планами матриці Адамара . Звичайно, ви не повинні використовувати всі доступні фактори в цих планах, і, насправді, іноді ви хочете створити насичений дизайн для ще одного фактора, ніж ви очікуєте перевірити.
Покращення роздільної здатності дизайну за допомогою Foldover
Один із способів, за допомогою якого проект роздільної здатності III може бути покращений і перетворений у дизайн роздільної здатності IV, — це за допомогою згортання (наприклад, див. Box and Draper, 1987, Deming and Morgan, 1993): Припустімо, що у вас є 7-факторний дизайн у 8 прогонах:
| Дизайн: 2**(7-4) дизайн | |||||||
|---|---|---|---|---|---|---|---|
| бігти | А | Б | C | Д | E | Ф | Г |
| 1 2 3 4 5 6 7 8 |
1 1 1 1 -1 -1 -1 -1 |
1 1 -1 -1 1 1 -1 -1 |
1 -1 1 -1 1 -1 1 -1 |
1 1 -1 -1 -1 -1 1 1 |
1 -1 1 -1 -1 1 -1 1 |
1 -1 -1 1 1 -1 -1 1 |
1 -1 -1 1 -1 1 1 -1 |
Це проект роздільної здатності III, тобто двосторонні взаємодії будуть змішані з основними ефектами. Ви можете перетворити цей дизайн на дизайн роздільної здатності IV за допомогою параметра Foldover (підвищити роздільну здатність). Метод згортання копіює весь дизайн і додає його в кінець, змінюючи всі знаки:
| Дизайн: 2**(7-4) дизайн (+Foldover) | ||||||||
|---|---|---|---|---|---|---|---|---|
| бігти |
А |
Б |
C |
Д |
E |
Ф |
Г |
Нове: Х |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 1 1 1 1 |
1 1 -1 -1 1 1 -1 -1 -1 -1 1 1 -1 -1 1 1 |
1 -1 1 -1 1 -1 1 -1 -1 1 -1 1 -1 1 -1 1 |
1 1 -1 -1 -1 -1 1 1 -1 -1 1 1 1 1 -1 -1 |
1 -1 1 -1 -1 1 -1 1 -1 1 -1 1 1 -1 1 -1 |
1 -1 -1 1 1 -1 -1 1 -1 1 1 -1 -1 1 1 -1 |
1 -1 -1 1 -1 1 1 -1 -1 1 1 -1 1 -1 -1 1 |
1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 |
Таким чином, стандартний прогін номер 1 був -1, -1, -1, 1, 1, 1, -1 ; новий прогін під номером 9 (перший прогін «розгорнутої» частини) має всі знаки на протилежні: 1, 1, 1, -1, -1, -1, 1 . Окрім покращення роздільної здатності дизайну, ми також отримали 8-й фактор (фактор H ), який містить усі +1 для перших восьми запусків і -1 для складеної частини нового дизайну. Зауважте, що результуючий дизайн насправді є дизайном 2**(8-4) резолюції IV (див. також Box and Draper, 1987, стор. 160).
Псевдоніми взаємодій: генератори дизайну
Щоб повернутися до прикладу розробки роздільної здатності R = III , тепер, коли ви знаєте, що основні ефекти змішуються з двосторонніми взаємодіями , ви можете поставити запитання: «Яка взаємодія змішується з яким основним ефектом?»
| Фактор |
Fractional Design Generators 2**(11-7) design (Фактори позначаються цифрами) Псевдонім |
|---|---|
| 5 6 7 8 9 10 11 |
123 234 134 124 1234 12 13 |
Конструкція генераторів. Наведені вище генератори дизайну є «ключем» до того, як генерувалися фактори з 5 по 11 шляхом призначення їх конкретним взаємодіям перших 4 факторів повного факторіального плану 2**4. Зокрема, фактор 5 ідентичний взаємодії 123 (фактор 1 за фактором 2 за фактором 3). Фактор 6 ідентичний взаємодії 234 і так далі. Пам’ятайте, що проект має роздільну здатність III (три), і ви очікуєте, що деякі основні ефекти будуть змішані з деякими двосторонніми взаємодіями; дійсно, фактор 10 (десять) ідентичний взаємодії 12 (фактор 1 за фактором 2), а фактор11 (одинадцять) ідентична взаємодії 13 (фактор 1 за фактором 3). Інший спосіб, у який часто виражають ці еквівалентності, полягає в тому, що головним ефектом для фактора 10 (десять) є псевдонім для взаємодії 1 на 2. (Термін псевдонім вперше використав Фінні, 1945).
Підводячи підсумок, щоразу, коли ви хочете включити менше спостережень (прогонів) у свій експеримент, ніж це вимагається для повного факторіального дизайну 2**k, ви «жертвуєте» ефектами взаємодії та призначаєте їх рівням факторів. Отриманий дизайн більше не є повним факторіалом, а дробовим факторіалом.
Фундаментальна ідентичність. Інший спосіб узагальнити генератори дизайну - це просте рівняння. А саме, якщо, наприклад, фактор 5 у дробовому факторіальному плані ідентичний взаємодії 123 (фактор 1 на фактор 2 на фактор 3 ), то з цього випливає, що множення кодованих значень для взаємодії 123 на кодовані значення для фактора 5 завжди призведе до +1 (якщо всі рівні факторів кодуються �1 ); або:
I = 1235
де I означає +1 (з використанням стандартної нотації, як, наприклад, у Box and Draper, 1987). Таким чином, ми також знаємо, що фактор 1 плутається з взаємодією 235 , фактор 2 з взаємодією 135 , а фактор 3 з взаємодією 125 , тому що в кожному випадку їх добуток має дорівнювати 1 . Змішування двосторонніх взаємодій також визначається цим рівнянням, оскільки взаємодія 12 , помножена на взаємодію 35 , має давати 1, а отже, вони ідентичні або змішані. Таким чином, можна підсумувати всі плутанини в дизайні за допомогою такого фундаментального рівняння тотожності .
Блокування
У деяких виробничих процесах одиниці виробляються природними «шматками» або блоками. Ви хочете переконатися, що ці блоки не змінюють ваші оцінки основних ефектів. Наприклад, у вас може бути піч для виробництва спеціальної кераміки, але розмір печі обмежений, тому ви не можете виготовити всі цикли свого експерименту одночасно. У цьому випадку вам потрібно розбити експеримент на блоки. Однак ви не хочете запускати позитивні налаштування всіх факторів в одному блоці, а всі негативні налаштування в іншому. В іншому випадку будь-які випадкові відмінності між блоками систематично впливатимуть на всі оцінки основних ефектів факторів, що цікавлять. Швидше, ви хочете розподілити прогони між блоками, щоб будь-які відмінності між блоками (тобто коефіцієнт блокування) не зміщуйте свої результати щодо факторних ефектів, які вас цікавлять. Це досягається шляхом розгляду фактора блокування як іншого фактора в дизайні. Отже, ви «втрачаєте» ще один ефект взаємодії через фактор блокування, і кінцевий дизайн матиме нижчу роздільну здатність. Однак ці схеми часто мають перевагу статистично більшої потужності, оскільки вони дозволяють оцінювати та контролювати мінливість у виробничому процесі, яка є результатом відмінностей між блоками.
Тиражування дизайну
Іноді бажано відтворити проект, тобто виконати кожну комбінацію рівнів факторів у проекті кілька разів. Це дозволить пізніше оцінити так звану чисту похибкув експерименті. Аналіз експериментів далі обговорюється нижче; однак має бути зрозуміло, що при повторенні дизайну можна обчислити мінливість вимірювань у межах кожної унікальної комбінації рівнів факторів. Ця мінливість дасть вказівку на випадкову похибку у вимірюваннях (наприклад, через неконтрольовані фактори, ненадійність вимірювального приладу тощо), оскільки повторювані спостереження проводяться за ідентичних умов (налаштувань рівнів факторів). Така оцінка чистої помилки може бути використана для оцінки розміру та статистичної значущості мінливості, яку можна віднести до маніпулюваних факторів.
Часткові реплікації.Коли неможливо або неможливо відтворити кожну унікальну комбінацію рівнів факторів (тобто повний дизайн), можна отримати оцінку чистої помилки, відтворивши лише деякі прогони в експерименті. Однак слід бути обережним, враховуючи можливе зміщення, яке може бути внесене вибірковим тиражуванням лише деяких циклів. Якщо тиражувати лише ті прогони, які найлегше повторити (наприклад, збирати інформацію в точках, де вона «найдешевша»), можна ненавмисно вибрати лише ті комбінації рівнів факторів, які призводять до дуже малої (або дуже великої) випадкової мінливості. -- змушуючи недооцінювати (або переоцінювати) справжню кількість чистої помилки. Таким чином, слід уважно розглянути, як правило, на основі ваших знань про процес, який вивчається, які цикли слід відтворити, тобто
Додавання центральних точок
Конструкції з факторами, встановленими на двох рівнях, неявно припускають, що вплив факторів на залежну змінну інтересу (наприклад, міцність тканини ) є лінійним. Неможливо перевірити, чи існує нелінійна (наприклад, квадратична) складова у зв’язку між фактором А та залежною змінною, якщо А оцінюється лише за двома точками (тобто за низькою та високоюналаштування). Якщо хтось підозрює, що зв’язок між факторами в плані та залежною змінною є радше кривою лінійною, тоді слід включити один або більше циклів, де всі (безперервні) фактори встановлено в середній точці. Такі лінії називаються центральними точками (або центральними точками), оскільки вони, у певному сенсі, знаходяться в центрі дизайну (див. графік).
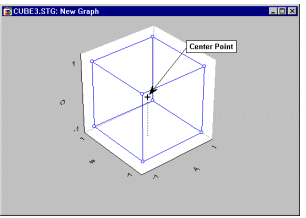
Пізніше під час аналізу (див. нижче) можна порівняти вимірювання для залежної змінної в центральній точці із середнім для решти проекту. Це забезпечує перевірку кривизни (див. Box and Draper, 1987): якщо середнє для залежної змінної в центрі плану значно відрізняється від загального середнього в усіх інших точках плану, то є вагомі підстави вважати що просте припущення про те, що фактори лінійно пов’язані із залежною змінною, не виконується.
Аналіз результатів експерименту 2**(kp).
Дисперсійний аналіз. Далі потрібно точно визначити, який із факторів суттєво вплинув на залежну змінну, що цікавить. Наприклад, у дослідженні, опублікованому Боксом і Дрейпером (1987, сторінка 115), бажано дізнатися, які з факторів, задіяних у виробництві барвників, впливають на міцність тканини. У цьому прикладі фактори 1 ( полісульфід ), 4 ( час ) і 6 ( температура ) значно вплинули на міцність тканини. Зауважте, що для спрощення нижче показано лише основні ефекти.
| ANOVA; Вар.:СИЛА; R-sqr = 0,60614; Adj:.56469 (fabrico.sta) | |||||
|---|---|---|---|---|---|
| 2**(6-0) дизайн; MS Залишок = 3,62509 DV: МІЦНІСТЬ |
|||||
| SS | df | РС | Ф | стор | |
| (1)POLYSUFD (2) REFLUX (3)MOLES (4)TIME (5)SOLVENT (6)TEMPERTR Помилка Total SS |
48,8252 7,9102 ,1702 142,5039 2,7639 115,8314 206,6302 524,6348 |
1 1 1 1 1 1 57 63 |
48,8252 7,9102 0,1702 142,5039 2,7639 115,8314 3,6251 |
13,46867 2,18206 ,04694 39,31044 , 76244 31,95269 |
.000536 .145132 .829252 .000000 .386230 .000001 |
Чиста помилка та невідповідність. Якщо план експерименту принаймні частково повторюється, тоді можна оцінити мінливість помилки для експерименту на основі мінливості повторених циклів. Оскільки ці вимірювання проводилися в ідентичних умовах, тобто при ідентичних налаштуваннях рівнів факторів, оцінка мінливості помилки з цих прогонів не залежить від того, чи є «справжня» модель лінійною чи нелінійною за своєю природою, або включає взаємодії вищого порядку . Розрахована таким чином мінливість помилки є чистою помилкою, тобто це повністю пов’язано з ненадійністю вимірювання залежної змінної. Якщо доступно, можна використати оцінку чистої помилки для перевірки значущості залишкової дисперсії, тобто всієї залишкової мінливості, яка не може бути врахована факторами та їх взаємодією, які зараз присутні в моделі. Якщо фактично залишкова мінливість значно більша, ніж мінливість чистої помилки, тоді можна зробити висновок, що все ще залишається деяка статистично значуща мінливість, яка пояснюється відмінностями між групами, і, отже, існує загальна відсутність відповідності поточної моделі.
| ANOVA; Вар.:СИЛА; R-sqr = 0,58547; Adj:.56475 (fabrico.sta) | |||||
|---|---|---|---|---|---|
| 2**(3-0) дизайн; MS Pure Error = 3,594844 DV: СИЛА |
|||||
| SS | df | РС | Ф | стор | |
| (1)POLYSUFD (2)TIME (3)TEMPERTR Відсутність відповідності Чиста помилка Загальна SS |
48,8252 142,5039 115,8314 16,1631 201,3113 524,6348 |
1 1 1 4 56 63 |
48,8252 142,5039 115,8314 4,0408 3,5948 |
13,58200 39,64120 32,22154 1,12405 |
.000517 .000000 .000001 .354464 |
Наприклад, у наведеній вище таблиці показано результати для трьох факторів, які раніше були визначені як найважливіші щодо їхнього впливу на міцність тканини; всі інші фактори були проігноровані в аналізі. Як ви можете бачити в рядку з позначкою « Відсутність відповідності» , коли залишкова мінливість для цієї моделі (тобто після видалення трьох основних ефектів) порівнюється з чистою помилкою, оціненою на основі мінливості всередині групи, результат F - критерію не є статистично значущим. Таким чином, цей результат додатково підтверджує висновок про те, що дійсно фактори Полісульфід, Час і Температура значно вплинули на результуючу міцність тканини адитивним чином (тобто немає ніяких взаємодій). Або, іншими словами, усі відмінності між середніми значеннями, отриманими в різних експериментальних умовах, можна достатньо пояснити простою адитивною моделлю для цих трьох змінних.
Оцінки параметрів або ефектів. Тепер подивіться, як ці фактори вплинули на міцність тканин.
| Ефект | Стандартна помилка | т (57) | стор | |
|---|---|---|---|---|
| Середнє/Інтерк. (1)ПОЛІСУФД (2) РЕФЛЕКС (3)МОЛЬ (4)ЧАС (5)РОЗЧИННИК (6)ТЕМПЕРТ |
11,12344 1,74688 ,70313 ,10313 2,98438 -, 41562 2,69062 |
.237996 .475992 .475992 .475992 .475992 .475992 .475992 |
46,73794 3,66997 1,47718 ,21665 6,26980 -, 87318 5,65267 |
.000000 .000536 .145132 .829252 .000000 .386230 .000001 |
Наведені вище числа є оцінками ефекту або параметра. За винятком загального середнього значення/перехоплення , ці оцінки є відхиленнями середнього значення негативних налаштувань від середнього значення позитивних налаштувань для відповідного фактора. Наприклад, якщо ви зміните налаштування фактора часу з низького на високий , ви можете очікувати покращення сили на 2,98 ; якщо встановити високе значення фактора Polysulfd , ви можете очікувати подальшого покращення на 1,75 і так далі.
Як ви можете бачити, ті самі три фактори, які були статистично значущими, показують найбільші оцінки параметрів; таким чином налаштування цих трьох факторів були найважливішими для кінцевої міцності тканини.
Для аналізів, включаючи взаємодії , інтерпретація параметрів ефекту є дещо складнішою. Зокрема, параметри двосторонньої взаємодії визначаються як половина різниці між основними ефектами одного фактора на двох рівнях другого фактора (див. Mason, Gunst і Hess, 1989, стор. 127); так само, параметри тристоронньої взаємодії визначаються як половина різниці між ефектами двофакторної взаємодії на двох рівнях третього фактора тощо.
Коефіцієнти регресії. Можна також переглянути параметри в моделі множинної регресії (див . Множинна регресія ). Щоб продовжити цей приклад, розглянемо наступне рівняння передбачення:
Міцність = const + b 1 *x 1 +... + b 6 *x 6
Тут від x 1 до x 6 позначають 6 факторів в аналізі. Показані раніше оцінки ефекту також містять такі оцінки параметрів:
| коеф. |
Стандартна помилка коеф. |
-95.% Cnf.Limt |
+95.% Cnf.Limt |
|
|---|---|---|---|---|
| Середнє/Інтерк. (1)ПОЛІСУФД (2) РЕФЛЕКС (3)МОЛЬ (4)ЧАС (5)РОЗЧИННИК (6)ТЕМПЕРТ |
11,12344 ,87344 ,35156 ,05156 1,49219 -, 20781 1,34531 |
.237996 .237996 .237996 .237996 .237996 .237996 .237996 |
10,64686 ,39686 -,12502 -,42502 1,01561 -, 68439 , 86873 |
11,60002 1,35002 ,82814 ,52814 1,96877 , 26877 1,82189 |
Насправді ці параметри містять мало «нової» інформації, оскільки вони складають лише половину значень параметра (за винятком середнього значення/перехоплення ), показаних раніше. Це має сенс, оскільки тепер коефіцієнт можна інтерпретувати як відхилення високого значення для відповідних факторів від центру. Однак зауважте, що це стосується лише випадків, коли значення факторів (тобто їхні рівні) кодуються як -1 і +1 відповідно. В іншому випадку масштабування значень факторів вплине на величину оцінок параметрів. У прикладі даних, представлених Боксом і Дрейпером (1987, сторінка 115), параметри або значення для різних факторів були записані в дуже різних масштабах:
| файл даних: FABRICO.STA [ 64 випадки з 9 змінними ] 2**(6-0) Design, Box & Draper, с. 117 |
|||||||||
|---|---|---|---|---|---|---|---|---|---|
| ПОЛІСУФД | РЕФЛЮКС | КРОТИ | ЧАС | РОЗЧИННИК | TEMPERTR | СИЛА | HUE | ЯСКРАВОСТІ | |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 . . . |
6 7 6 7 6 7 6 7 6 7 6 7 6 7 6 . . . |
150 150 170 170 150 150 170 170 150 150 170 170 150 150 170 . . . |
1,8 1,8 1,8 1,8 2,4 2,4 2,4 2,4 1,8 1,8 1,8 1,8 2,4 2,4 2,4 . . . |
24 24 24 24 24 24 24 24 36 36 36 36 36 36 36 . . . |
30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 . . . |
120 120 120 120 120 120 120 120 120 120 120 120 120 120 120 . . . |
3,4 9,7 7,4 10,6 6,5 7,9 10,3 9,5 14,3 10,5 7,8 17,2 9,4 12,1 9,5 . . . |
15,0 5,0 23,0 8,0 20,0 9,0 13,0 5,0 23,0 1,0 11,0 5,0 15,0 8,0 15,0 . . . |
36,0 35,0 37,0 34,0 30,0 32,0 28,0 38,0 40,0 32,0 32,0 28,0 34,0 26,0 30,0 . . . |
Нижче наведено оцінки коефіцієнта регресії на основі некодованих вихідних значень фактора:
| Regressn Coeff. |
Стандартна помилка |
т (57) |
стор |
|
|---|---|---|---|---|
| Середнє/Інтерк. (1)ПОЛІСУФД (2) РЕФЛЕКС (3)МОЛЬ (4)ЧАС (5)РОЗЧИННИК (6)ТЕМПЕРТ |
-46,0641 1,7469 ,0352 ,1719 , 2487 -, 0346 , 2691 |
8.109341 .475992 .023800 .793320 .039666 .039666 .047599 |
-5,68037 3,66997 1,47718 ,21665 6,26980 -, 87318 5,65267 |
.000000 .000536 .145132 .829252 .000000 .386230 .000001 |
Оскільки метрика для різних факторів більше не сумісна, величини коефіцієнтів регресії також несумісні. Ось чому зазвичай більш інформативно дивитися на оцінки параметрів ANOVA (для закодованих значень рівнів факторів), як показано раніше. Однак коефіцієнти регресії можуть бути корисними, коли потрібно зробити прогнози для залежної змінної на основі вихідної метрики факторів.
Параметри графіка
Діагностичні графіки залишків. Почнемо з того, що перш ніж прийняти конкретну «модель», яка включає певну кількість ефектів (наприклад, основні ефекти для полісульфіду, часу та температури в поточному прикладі), слід завжди вивчати розподіл залишкових значень. Вони обчислюються як різниця між прогнозованими значеннями (як передбачено поточною моделлю) і спостережуваними значеннями. Ви можете обчислити гістограму для цих залишкових значень, а також графіки ймовірностей (як показано нижче).
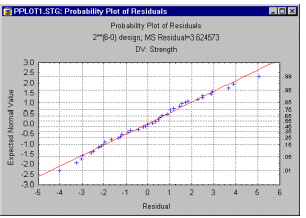
Оцінки параметрів і таблиця ANOVA базуються на припущенні, що залишки розподілені нормально (див. також Основні поняття ). Гістограма є одним із способів перевірити (візуально), чи справджується це припущення. Так званий графік нормальної ймовірності є ще одним поширеним інструментом для оцінки того, наскільки набір спостережуваних значень (у цьому випадку залишків) відповідає теоретичному розподілу. На цьому графіку фактичні залишкові значення відкладені вздовж горизонтальної осі X ; вертикальна вісь Y показує очікувані нормальні значення для відповідних значень після їх упорядкування за рангом. Якщо всі значення потрапляють на пряму лінію, то можна бути впевненим, що залишки відповідають нормальному розподілу.
Діаграма ефектів Парето. Діаграма ефектів Парето часто є ефективним інструментом для повідомлення результатів експерименту, зокрема непрофесіоналам.
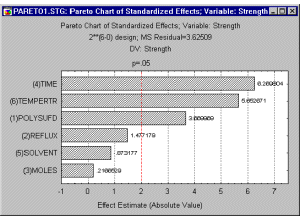
На цьому графіку оцінки ефекту ANOVA відсортовані від найбільшого абсолютного значення до найменшого абсолютного значення. Величина кожного ефекту представлена стовпцем, і часто лінія, що проходить через стовпці, вказує, наскільки великим має бути ефект (тобто, якою довжиною має бути стовпець), щоб він був статистично значущим.
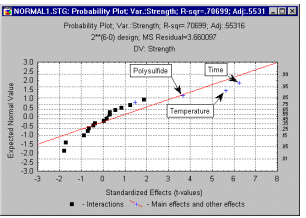
Нормальний ймовірнісний графік ефектів. Іншим корисним, хоча й більш технічним підсумковим графіком, є звичайний ймовірнісний графік оцінок. Як і на звичайному ймовірнісному графіку залишків, спочатку оцінки ефекту впорядковуються за рангом, а потім обчислюється нормальний z - рахунок на основі припущення, що оцінки розподілені нормально. Цей показник z відкладено на осі Y ; спостережувані оцінки відкладаються на осі X (як показано нижче).
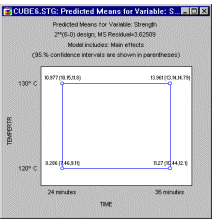
Квадратні та кубічні ділянки. Ці графіки часто використовуються для узагальнення прогнозованих значень для залежної змінної, враховуючи відповідні високі та низькі параметри факторів. Квадратний графік (див. нижче) покаже прогнозовані значення (і, за бажанням, їхні довірчі інтервали) для двох факторів одночасно. Кубічний графік показуватиме прогнозовані значення (і, за бажанням, довірчі інтервали) для трьох факторів одночасно.
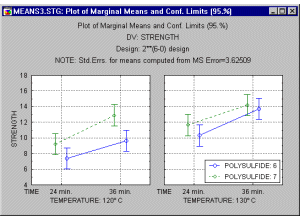
Сюжети взаємодії. Загальним графіком для відображення середніх є стандартний графік взаємодії, де середні позначені точками, з’єднаними лініями. Цей графік (див. нижче) особливо корисний, коли в моделі є значні ефекти взаємодії.
Поверхневі та контурні епюри. Коли фактори в плані є безперервними за своєю природою, часто також корисно дивитися на поверхневі та контурні графіки залежної змінної як функцію факторів.
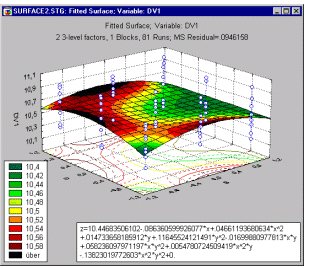
Ці типи графіків будуть обговорюватися далі в цьому розділі в контексті 3**(kp), а також дизайну центральної композитної поверхні та поверхні відгуку.
Резюме
Конструкції 2**(kp) є «робочою конячкою» промислових експериментів. Вплив великої кількості факторів на виробничий процес можна одночасно оцінити з відносною ефективністю (тобто за допомогою кількох експериментальних серій). Логіка цих типів експериментів проста (кожен фактор має лише два налаштування).
Недоліки. Простота цих конструкцій також є їх головним недоліком. Як згадувалося раніше, в основі використання дворівневих факторів лежить переконання, що результуючі зміни в залежній змінній (наприклад, міцність тканини) є в основному лінійними за своєю природою. Це часто не так, і багато змінних пов’язані з характеристиками якості нелінійним чином. У наведеному вище прикладі, якби ви постійно збільшували температурний фактор (який суттєво пов’язувався з міцністю тканини), ви, звичайно, врешті-решт досягли б «піка», і з цього моменту міцність тканини зменшувалася б із підвищенням температури. Хоча це види кривизниу взаємозв’язку між факторами в дизайні та залежною змінною можна виявити, якщо проект включав пробіги центральної точки, неможливо підібрати явні нелінійні (наприклад, квадратичні) моделі з планами 2**(kp) (проте, центральні складені плани будуть зробіть саме це).
Іншою проблемою дробових планів є неявне припущення, що взаємодії вищого порядку не мають значення; але іноді вони трапляються, наприклад, коли деякі інші фактори встановлені на певному рівні, температура може бути негативно пов’язана з міцністю тканини. Знову ж таки, у дробових факторних планах взаємодії вищого порядку (більші, ніж двосторонні) особливо не будуть виявлені.
| Індексувати |
2 **( kp ) Дробові факториальні схеми часто використовуються в промислових експериментах через економію збору даних, яку вони забезпечують. Наприклад, припустімо, що інженеру потрібно дослідити вплив різних 11 факторів, кожен з яких має 2 рівні, на виробничий процес. Назвемо число факторів k , яке для цього прикладу дорівнює 11. Експеримент із використанням повного факторного плану, де вивчаються ефекти кожної комбінації рівнів кожного фактора, вимагатиме 2 **( k) експериментальних прогонів, або 2048 прогонів для цього прикладу. Щоб звести до мінімуму зусилля зі збору даних, інженер може вирішити відмовитися від дослідження ефектів взаємодії 11 факторів вищого порядку та зосередитися замість цього на визначенні основних ефектів 11 факторів і будь-яких ефектів взаємодії нижчого порядку, які можна оцінити за допомогою експериментуйте з меншою, більш прийнятною кількістю експериментальних прогонів. Існує ще одна, більш теоретична причина, чому не варто проводити величезні, повні експерименти з факторним 2-м рівнем. Загалом, нелогічно займатися виявленням ефектів взаємодії вищого порядку експериментальних факторів, ігноруючи нелінійні ефекти нижчого порядку, такі як квадратичні або кубічні ефекти, які неможливо оцінити, якщо використовуються лише 2 рівні кожного фактора .
Альтернативою 2 **( k ) повному факторіальному плану є 2 **( kp ) дробовий факторіальний план, який вимагає лише «частки» зусиль зі збору даних, необхідних для повного факторіального плану. Для нашого прикладу з k = 11 факторів, якщо можна провести лише 64 експериментальні прогони, 2**(11-5) фракційний факторний експеримент буде розроблено з 2**6 = 64 експериментальними прогонами. По суті, проектується kp = 6-сторонній повний факторний експеримент, при цьому рівні факторів p «генеруються» рівнями вибраних взаємодій вищого порядкуз інших 6 факторів. Дробові факторіали «жертвують» ефектами взаємодії вищого порядку, щоб ефекти нижчого порядку все ще можна було правильно обчислити. Однак різні критерії можуть використовуватися при виборі взаємодій вищого порядку, які будуть використовуватися як генератори, причому різні критерії іноді призводять до різних «найкращих» дизайнів.
2 **( kp ) Дробові факториальні плани можуть також включати блокуючі фактори. У деяких виробничих процесах одиниці виробляються природними «шматками» або блоками. Щоб переконатися, що ці блоки не зміщують ваші оцінки ефектів для факторів k , фактори блокування можна додати як додаткові фактори в плані. Отже, ви можете «пожертвувати» додатковими ефектами взаємодії для генерації факторів блокування, але ці конструкції часто мають перевагу статистично більшої потужності, оскільки вони дозволяють оцінювати та контролювати мінливість у виробничому процесі, яка зумовлена відмінностями між блоками .
Критерії проектування
Багато концепцій, розглянутих у цьому огляді, також розглядаються в Огляді 2**(kp) дробових факторіальних планів . Однак технічний опис того, як будуються дробові факторні плани, виходить за межі будь-якого вступного огляду. Докладні відомості про те, як розробити 2 **( kp ) експерименти, можна знайти, наприклад, у Bayne and Rubin (1986), Box and Draper (1987), Box, Hunter, and Hunter (1978), Montgomery (1991), Деніел (1976), Демінг і Морган (1993), Мейсон, Ганст і Гесс (1989) або Райан (1989) — це лише деякі з багатьох підручників на цю тему.
Загалом, методи 2**(kp) максимальної неконфігурації та мінімальної аберації послідовно вибиратимуть, які взаємодії вищого порядку використовувати як генератори для факторів p . Наприклад, розглянемо наступний план, який включає 11 факторів, але вимагає лише 16 прогонів (спостережень).
| Дизайн: 2**(11-7), резолюція III | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| бігти | А | Б | C | Д | E | Ф | Г | Х | я | Дж | К |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 |
1 1 1 1 -1 -1 -1 -1 1 1 1 1 -1 -1 -1 -1 |
1 1 -1 -1 1 1 -1 -1 1 1 -1 -1 1 1 -1 -1 |
1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 1 -1 |
1 1 -1 -1 -1 -1 1 1 -1 -1 1 1 1 1 -1 -1 |
1 -1 -1 1 -1 1 1 -1 1 -1 -1 1 -1 1 1 -1 |
1 -1 -1 1 1 -1 -1 1 -1 1 1 -1 -1 1 1 -1 |
1 -1 1 -1 -1 1 -1 1 -1 1 -1 1 1 -1 1 -1 |
1 -1 -1 1 -1 1 1 -1 -1 1 1 -1 1 -1 -1 1 |
1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 1 1 1 1 |
1 1 -1 -1 1 1 -1 -1 -1 -1 1 1 -1 -1 1 1 |
Інтерпретація дизайну. Дизайн, показаний на аркуші прокрутки вище, слід інтерпретувати наступним чином. Кожен стовпець містить +1 або -1, щоб вказати налаштування відповідного коефіцієнта (високий або низький відповідно). Так, наприклад, у першому прогоні експерименту для всіх факторів від A до K встановлено вищий рівень, а під час другого запуску для факторів A , B і C встановлено вищий рівень, але для фактора D встановлено значення нижній рівень і так далі. Зауважте, що налаштування для кожного експериментального циклу для фактора E можна отримати шляхом множення відповідних параметрів для факторів A , B іC . Тому ефект взаємодії A x B x C не можна оцінити незалежно від ефекту фактора E у цій конструкції, оскільки ці два ефекти змішані. Подібним чином параметри для фактора F можна отримати шляхом множення відповідних параметрів для факторів B , C і D. Ми говоримо, що ABC і BCD є твірними для множників E і F відповідно.
Критерій проектування максимальної роздільної здатності. На аркуші прокрутки, показаному вище, дизайн описано як дизайн 2**(11-7) роздільної здатності III (три). Це означає, що ви вивчаєте загалом k = 11 факторів, але p = 7 із цих факторів були створені в результаті взаємодії повного 2**[(11-7) = 4] факторного плану. Як наслідок, дизайн не забезпечує повної роздільної здатності ; тобто існують певні ефекти взаємодії, які змішуються з (ідентичними) іншим ефектам. Загалом, схема роздільної здатності R є такою, де жодна l -стороння взаємодія не змішується з будь-якою іншою взаємодією порядку меншого за R-l. У поточному прикладі R дорівнює 3. Тут жодна взаємодія l = 1 (тобто основні ефекти) не плутається з будь-якою іншою взаємодією порядку меншого за R - l = 3 -1 = 2. Таким чином, основні ефекти у цьому дизайні не змішуються один з одним, але змішуються двофакторними взаємодіями; і, отже, з іншими взаємодіями вищого порядку. Один очевидний, але, тим не менш, дуже важливий загальний критерій проектування полягає в тому, що взаємодії вищого порядку, які будуть використовуватися як генератори, слід вибирати таким чином, щоб роздільна здатність проекту була якомога вищою.
Максимальний безперешкодний критерій дизайну. Однак максимізація роздільної здатності конструкції сама по собі не гарантує, що вибрані генератори створять «найкращу» конструкцію. Розглянемо, наприклад, дві різні конструкції роздільної здатності IV. В обох моделях основні ефекти не будуть змішані один з одним, а двофакторні взаємодії не будуть змішані з основними ефектами, тобто ніякі l = 2-сторонні взаємодії не будуть змішані з будь-якою іншою взаємодією порядку меншого за R - l = 4 - 2 . = 2. Однак ці два дизайни можуть відрізнятися щодо ступеня змішування для двофакторних взаємодій. Для проектів із роздільною здатністю IV «вирішальний порядок», у якому вперше з’являється змішування ефектів, стосується двофакторних взаємодій. В одному дизайні жоден із «вирішальних порядків» 2-факторних взаємодій не може бути незміщеним з усіма іншими 2-факторними взаємодіями, тоді як в іншому дизайні практично всі 2-факторні взаємодії можуть бути не змішаними з усіма іншими 2 -факторні взаємодії. Другий дизайн «майже роздільної здатності V» був би кращим перед першим дизайном «ледве роздільної здатності IV». Це свідчить про те, що навіть незважаючи на те, що критерій проектування максимальної роздільної здатності має бути основним критерієм, допоміжним критерієм може бути те, що генератори слід вибирати таким чином, щоб максимальна кількість взаємодій, менша або рівна вирішальному порядку, з огляду на роздільну здатність, не плуталася з всі інші взаємодії вирішального порядку. Це називається критерієм максимального безперешкодного проектування та є одним із необов’язкових,2**(kp) дизайн.
Критерій проектування мінімальної аберації. Критерій мінімальної аберації є ще одним необов’язковим, допоміжним критерієм для використання в пошуку схеми 2**(kp) . У деяких аспектах цей критерій схожий на критерій максимального безперешкодного проектування. Технічно план мінімальної аберації визначається як дизайн максимальної роздільної здатності, «який мінімізує кількість слів у визначальному відношенні, які мають мінімальну довжину» (Fries & Hunter, 1984). Менш технічно, критерій, очевидно, працює шляхом вибору генераторів, які створюють найменшу кількість пар змішаних взаємодій вирішального порядку. Наприклад, конструкція IV з мінімальною роздільною здатністю аберації матиме мінімальну кількість пар змішаних 2-факторних взаємодій.
Щоб проілюструвати різницю між критеріями максимальної непоміченості та мінімальної аберації, розглянемо схему максимальної неперешкоди 2**(9-4) і мінімальну аберацію 2**(9-4), як, наприклад, перераховано в Box, Hunter, і Хантер (1978). Якщо ви порівняєте ці два дизайни, ви побачите, що в максимально неконфундованому плані 15 із 36 двофакторних взаємодійне змішуються з будь-якими іншими 2-факторними взаємодіями, тоді як у дизайні мінімальної аберації лише 8 із 36 2-факторних взаємодій не змішуються з будь-якими іншими 2-факторними взаємодіями. Проте мінімальний дизайн аберації створює 18 пар змішаних взаємодій, тоді як максимально необґрунтований дизайн створює 21 пару змішаних взаємодій. Таким чином, два критерії призводять до вибору генераторів, що виробляють різні «найкращі» конструкції.
На щастя, вибір щодо того, чи використовувати критерій максимальної непоміченості чи критерій мінімальної аберації, не впливає на обраний дизайн (за винятком, можливо, перемаркування факторів), коли факторів 11 або менше, за єдиним винятком: дизайн 2**(9-4), описаний вище (див. Chen, Sun, & Wu, 1993). Для проектів із більш ніж 11 факторами два критерії можуть призвести до вибору дуже різних дизайнів, і за браком кращих порад ми пропонуємо використовувати обидва критерії, порівнюючи створені дизайни та вибираючи дизайн, який найкраще відповідає вашим потребам . Редакційно ми додамо, що максимізація кількості повністю незрозумілих ефектів часто має більше сенсу, ніж мінімізація кількості пар змішаних ефектів.
Резюме
Дробові факториальні плани 2**(kp) є, ймовірно, найбільш часто використовуваним типом плану в промислових експериментах. Речі, які слід враховувати при розробці будь-якого 2 **( kp ) дробового факторного експерименту, включають кількість факторів, які потрібно дослідити, кількість експериментальних прогонів і чи будуть блоки експериментальних прогонів. Окрім цих базових міркувань, слід також взяти до уваги, чи дозволить кількість прогонів розробити дизайн необхідної роздільної здатності та ступеня змішування для вирішального порядку взаємодій , враховуючи роздільну здатність.
| Індексувати |
У деяких випадках необхідно перевірити фактори, які мають більше 2 рівнів. Наприклад, якщо хтось підозрює, що вплив факторів на залежну змінну, яка цікавить, не є просто лінійним, то, як обговорювалося раніше (див. схеми 2**(kp) ), потрібні принаймні 3 рівні, щоб перевірити на лінійні та квадратичні ефекти (і взаємодії ) для цих факторів. Крім того, іноді деякі фактори можуть бути категоричними за своєю природою, маючи більше ніж 2 категорії. Наприклад, у вас може бути три різні машини, які виготовляють певну деталь.
Проектування 3**(kp) експериментів
Загальний механізм генерації дробових факторіальних планів на 3 рівнях (схеми 3**(kp)) дуже подібний до описаного в контексті планів 2**(kp) . Зокрема, починається з повного факторного плану, а потім використовується взаємодія повного плану для побудови «нових» факторів (або блоків), роблячи їх рівні факторів ідентичними рівням відповідних умов взаємодії (тобто, роблячи нові фактори псевдоніми відповідних взаємодій).
Наприклад, розглянемо такий простий факторний план 3**(3-1):
| 3**(3-1) дробовий факторний план , 1 блок, 9 прогонів |
|||
|---|---|---|---|
| Стандартний запуск |
А |
Б |
C |
| 1 2 3 4 5 6 7 8 9 |
0 0 0 1 1 1 2 2 2 |
0 1 2 0 1 2 0 1 2 |
0 2 1 2 1 0 1 0 2 |
Як і у випадку планів 2**(kp), план створюється, починаючи з повного факторного плану 3-1=2 ; ці фактори перераховані в перших двох колонках (фактори A і B ). Фактор C побудований із взаємодії AB перших двох факторів. Зокрема, значення фактора C обчислюються як
C = 3 - мод 3 (A+B)
Тут mod 3 (x) означає так званий оператор за модулем 3 , який спочатку знаходить число y , яке менше або дорівнює x і яке рівномірно ділиться на 3, а потім обчислює різницю (залишок) між числом y і x . Наприклад, mod 3 (0) дорівнює 0 , mod 3 (1) дорівнює 1 , mod 3 (3) дорівнює 0 , mod 3 (5) дорівнює 2 ( 3найбільше число, яке менше або дорівнює 5 і ділиться на 3 рівномірно ; нарешті, 5-3=2 ), і так далі.
Фундаментальна ідентичність. Якщо застосувати цю функцію до суми стовпців A і B , показаних вище, ви отримаєте третій стовпець C. Подібно до випадку планів 2**(kp) (див. плани 2**(kp) для обговорення фундаментальна ідентичність у контексті дизайнів 2**(kp), це змішування взаємодій із «новими» основними ефектами можна підсумувати у виразі:
0 = мод 3 (A+B+C)
Якщо ви поглянете назад на схему 3**(3-1), показану раніше, ви побачите, що справді, якщо ви додасте числа в трьох стовпцях, усі вони складуть 0, 3 або 6 , тобто значення, які рівномірно діляться на 3 (і отже: mod 3 (A+B+C)=0) . Таким чином, можна було б записати як скорочену нотацію ABC=0, щоб узагальнити змішування факторів у дробовому дизайні 3**(kp).
Деякі з дизайнів матимуть фундаментальні ідентичності, які містять число 2 як множник; наприклад,
0 = мод 3 (B+C*2+D+E*2+F)
Це позначення можна інтерпретувати точно так само, як і раніше, тобто модуль 3 суми B+2*C+D+2*E+F має дорівнювати 0. Наступний приклад демонструє таку тотожність.
Приклад 3**(4-1) дизайн у 9 блоків
Ось підсумок для 4-факторного 3-рівневого дробового факторіального дизайну в 9 блоках, для якого потрібно лише 27 прогонів.
РЕЗЮМЕ: 3**(4-1) дробовий факторіал
Генератори дизайну: ABCD
Генератори блоків: AB,AC2
Кількість факторів (незалежних змінних): 4
Кількість циклів (випадки, експерименти): 27
Кількість блоків: 9
Цей дизайн дозволить перевірити лінійні та квадратичні основні ефекти для 4 факторів у 27 спостереженнях, які можна зібрати в 9 блоків по 3 спостереження в кожному. Фундаментальною ідентифікацією або генератором дизайну для дизайну є ABCD , таким чином модуль 3 суми рівнів факторів по чотирьох факторах дорівнює 0 . Фундаментальна ідентичність також дозволяє визначити змішування факторів і взаємодій у дизайні (докладніше див. McLean and Anderson, 1984).
| Unconfounded Effects (experi3.sta) | ||
|---|---|---|
| ЕКСПЕРИМ. ДИЗАЙН |
Список некорельованих факторів і взаємодій 3**(4-1) дробовий факторний дизайн, 9 блоків, 27 прогонів |
|
| Unconf. Ефекти (крім блоків) |
Без збентеження, якщо включені блоки? |
|
| 1 2 3 4 5 6 7 8 |
(1)A (L) A (Q) (2)B (L) B (Q) (3)C (L) C (Q) (4)D (L) D (Q) |
Так Так Так Так Так Так Так Так |
Як ви бачите, у цій конструкції 3**(4-1) основні ефекти не змішуються один з одним, навіть якщо експеримент виконується в 9 блоках.
Конструкції Box-Behnken
У випадку планів 2**(kp) Плакетт і Берман (1946) розробили сильно фракціоновані плани, щоб відібрати максимальну кількість (основних) ефектів у найменшій кількості експериментальних циклів. Еквівалентом у випадку планів 3**(kp) є так звані дизайни Box-Behnken (Box and Behnken, 1960; див. також Box and Draper, 1984). Ці проекти не мають простих генераторів проектів (вони створені шляхом об’єднання дворівневих факторних планів із неповними блоковими проектами) і мають складне змішування взаємодії. Однак конструкції є економічними і, отже, особливо корисними, коли проведення необхідних експериментів є дорогим.
Аналіз дизайну 3**(kp).
Аналіз цих типів проектів відбувається в основному так само, як було описано в контексті дизайнів 2**(kp) . Однак для кожного ефекту тепер можна перевірити лінійний ефект і квадратичний (нелінійний ефект). Наприклад, при вивченні виходу хімічного процесу температура може бути пов’язана нелінійним чином, тобто максимальний вихід може бути досягнутий, коли температура встановлена на середньому рівні. Таким чином, нелінійність часто виникає, коли процес працює поблизу свого оптимального.
Оцінки параметрів ANOVA
Щоб оцінити параметри дисперсійного аналізу, рівні факторів для факторів в аналізі внутрішньо перекодуються, щоб можна було перевірити лінійні та квадратичні компоненти у зв’язку між факторами та залежною змінною. Таким чином, незалежно від вихідної метрики налаштувань фактора (наприклад, 100 градусів C, 110 градусів C, 120 градусів C), ви завжди можете перекодувати ці значення до -1, 0 і +1 для виконання обчислень. Отримані оцінки параметрів ANOVA можна інтерпретувати аналогічно оцінкам параметрів для планів 2**(kp).
Наприклад, розглянемо такі результати ANOVA:
| Фактор | Ефект | Стандартна помилка | т (69) | стор |
|---|---|---|---|---|
| Середнє/Інтерк. БЛОКИ(1) БЛОКИ(2) (1)ТЕМПЕРАТ (L) ТЕМПЕРАТ (Q) (2)ЧАС (L) ЧАС (Q) (3)ШВИДКІСТЬ (L) ШВИДКІСТЬ (Q) 1L на 2L 1L на 2Q 1Q на 2L 1Q на 2Q |
103,6942 ,8028 -1,2307 -,3245 -,5111 ,0017 , 0045 -10,3073 -3,7915 3,9256 , 4384 , 4747 -2,7499 |
.390591 1.360542 1.291511 .977778 .809946 .977778 .809946 .977778 .809946 1.540235 1.371941 1.371941 .995575 |
265,4805 ,5901 -,9529 -,3319 -, 6311 , 0018 ,0056 -10,5415 -4,6812 2,5487 , 3195 , 3460 -2,7621 |
0.000000 .557055 .343952 .740991 .530091 .998589 .995541 .000000 .000014 .013041 .750297 .730403 .007353 |
Оцінки основного ефекту. За замовчуванням оцінку ефекту для лінійних ефектів (позначену літерою L біля назви фактора) можна інтерпретувати як різницю між середньою відповіддю при низьких і високих налаштуваннях для відповідних факторів. Оцінку квадратичного (нелінійного) ефекту (позначеного літерою Q біля назви фактора) можна інтерпретувати як різницю між середньою відповіддю при центральних (середніх) налаштуваннях і комбінованим високим і низьким налаштуваннями для відповідних факторів .
Оцінки ефекту взаємодії. Як і у випадку схем 2**(kp), ефект лінійної взаємодії можна інтерпретувати як половину різниці між лінійним основним ефектом одного фактора при високих і низьких налаштуваннях іншого. Аналогічно, взаємодію квадратичних компонентів можна інтерпретувати як половину різниці між квадратичним основним ефектом одного фактора при відповідних налаштуваннях іншого; тобто або високе, або низьке налаштування (квадратичне через лінійну взаємодію), або середнє або високе та низьке налаштування разом (квадратичне через квадратичну взаємодію).
На практиці та з точки зору «інтерпретованості результатів» зазвичай намагаються уникати квадратичних взаємодій . Наприклад, квадратична взаємодія A - by - B вказує на те, що нелінійний ефект фактора A модифікується нелінійним чином за допомогою параметра B. Це означає, що існує досить складна взаємодія між факторами, присутніми в даних, що ускладнить розуміння та оптимізацію відповідного процесу. Іноді виконання нелінійних перетворень (наприклад, виконання логарифмічного перетворення) значень залежних змінних може вирішити проблему.
Центровані та нецентровані поліноми. Як зазначалося вище, інтерпретація оцінок ефекту застосовується лише тоді, коли ви використовуєте стандартну параметризацію моделі. У цьому випадку ви будете кодувати взаємодії квадратичних факторів, щоб вони максимально «розплутувалися» з лінійними основними ефектами.
Графічне представлення результатів
Ті самі діаграми діагностики (наприклад, залишків) доступні для планів 3**(kp), як було описано в контексті планів 2**(kp) . Таким чином, перш ніж інтерпретувати остаточні результати, завжди спочатку слід дивитися на розподіл залишків для остаточної підігнаної моделі. Дисперсійний аналіз припускає, що залишки (помилки) розподілені нормально.
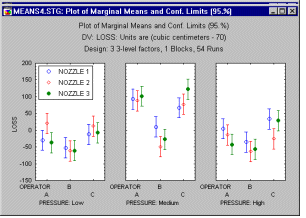
Сюжет засобів. Якщо взаємодія включає категоріальні фактори (наприклад, тип машини, конкретний оператор машини та певні чіткі налаштування машини), тоді найкращий спосіб зрозуміти взаємодію — це поглянути на відповідну діаграму засобів взаємодії.
Поверхнева ділянка. Якщо фактори взаємодії є безперервними за своєю природою, ви можете подивитися на графік поверхні, який показує поверхню відгуку, застосовану підігнаною моделлю. Зауважте, що цей графік також містить прогнозне рівняння (в термінах початкової метрики факторів), яке створює відповідну поверхню відгуку.
Дизайни для факторів на 2 і 3 рівнях
Ви також можете генерувати стандартні проекти з факторами рівня 2 і 3. Зокрема, ви можете генерувати стандартні проекти, перелічені Коннором і Янгом для Національного бюро стандартів США (див. Маклін і Андерсон, 1984). Технічні деталі методу, який використовується для створення цих дизайнів, виходять за рамки цього вступу. Однак загалом ця техніка є в певному сенсі комбінацією процедур, описаних у контексті дизайнів 2**(kp) і 3**(kp). Слід зауважити, однак, що, хоча всі ці конструкції дуже ефективні, вони не обов’язково ортогональні щодо всіх основних ефектів. Однак це не є проблемою, якщо використовувати загальний алгоритм для оцінки параметрів ANOVA та суми квадратів, який не вимагає ортогональності плану.
Розробка та аналіз цих експериментів відбуваються в тому ж ключі, що й у контексті експериментів 2**(kp) і 3**(kp).
| Індексувати |
Дизайни 2**(kp) і 3**(kp) вимагають, щоб рівні факторів були встановлені, наприклад, на 2 або 3 рівнях. У багатьох випадках такі плани неможливі, оскільки, наприклад, деякі комбінації факторів певним чином обмежені (наприклад, фактори A та B не можуть бути встановлені на високих рівнях одночасно). Крім того, з причин, пов’язаних з ефективністю, які будуть обговорюватися незабаром, часто бажано досліджувати експериментальну область інтересу в окремих точках, які не можуть бути представлені факторним планом.
Конструкції (і способи їх аналізу), які обговорюються в цьому розділі, стосуються оцінки (підгонки) поверхонь відгуку відповідно до загального рівняння моделі:
y = b 0 +b 1 *x 1 +...+b k *x k + b 12 *x 1 *x 2 +b 13 *x 1 *x 3 +...+b k-1,k * x k-1 *x k + b 11 *x 1 ² +...+b kk *x k ²
Говорячи словами, модель адаптується до спостережуваних значень залежної змінної y, яка включає (1) основні ефекти для факторів x 1 , ..., x k , (2) їх взаємодію ( x 1 *x 2 , x 1 *x 3 , ... ,x k-1 *x k ), і (3) їх квадратичні компоненти ( x 1 **2, ..., x k **2 ). Не робиться жодних припущень щодо «рівнів» факторів, і ви можете аналізувати будь-який набір безперервних значень для факторів.
Існують деякі міркування щодо ефективності проектування та упереджень, які призвели до стандартних проектів, які зазвичай використовуються, коли намагаються підібрати ці поверхні відгуку, і ці стандартні дизайни будуть обговорені незабаром (наприклад, див. Box, Hunter і Hunter, 1978; Box і Дрейпер, 1987; Хурі і Корнелл, 1987; Мейсон, Ганст і Гесс, 1989; Монтгомері, 1991). Але, як буде обговорено пізніше, в контексті дизайнів обмежених поверхонь і D- і A-оптимальних планів, ці стандартні конструкції іноді не можна використовувати з практичних причин. Однак параметри аналізу центрального комбінованого плану не роблять жодних припущень щодо структури вашого файлу даних, тобто кількості окремих значень факторів або їх комбінацій у ході експерименту, і, отже, ці параметри можна використовувати проаналізувати будь-який тип конструкції, підігнати до даних загальну модель, описану вище.
Проектні міркування
Ортогональні конструкції. Однією з бажаних характеристик будь-якого дизайну є те, що основний ефект і оцінки взаємодії, які цікавлять, не залежать одна від одної. Наприклад, припустімо, що ви провели двофакторний експеримент, з обома факторами на двох рівнях. Ваш дизайн складається з чотирьох прогонів:
| А | Б | |
|---|---|---|
| Біг 1 Біг 2 Біг 3 Біг 4 |
1 1 -1 -1 |
1 1 -1 -1 |
Для перших двох прогонів обидва фактори A і B встановлені на своїх високих рівнях ( +1 ). Під час останніх двох прогонів обидва встановлені на низькі рівні ( -1 ). Припустімо, ви хочете оцінити незалежні внески факторів A і B у прогнозування залежної змінної, яка вас цікавить. Очевидно, що це безглуздий дизайн, тому що немає способу оцінити основний ефект A та B. Можна оцінити лише один ефект — різницю між сеансами 1+2 і серіями 3+4 — який представляє сукупний ефект A і B.
Справа в тому, що для того, щоб оцінити незалежний внесок двох факторів, рівні факторів у чотирьох прогонах повинні бути встановлені так, щоб «стовпці» в дизайні (під A і B на ілюстрації вище) були незалежними від один одного. Інший спосіб виразити цю вимогу полягає в тому, щоб сказати, що стовпці проектної матриці (з стільки стовпців, скільки основних ефектів і параметрів взаємодії, які потрібно оцінити) повинні бути ортогональними (цей термін вперше використав Єйтс, 1933). Наприклад, якщо чотири прогони в проекті розташовані таким чином:
| А | Б | |
|---|---|---|
| Біг 1 Біг 2 Біг 3 Біг 4 |
1 1 -1 -1 |
1 -1 1 -1 |
тоді стовпці A і B ортогональні. Тепер ви можете оцінити основний ефект A , порівнюючи високий рівень для A на кожному рівні B з низьким рівнем для A на кожному рівні B ; основний ефект B можна оцінити таким же чином.
Технічно два стовпці в матриці дизайну є ортогональними, якщо сума добутків їхніх елементів у кожному рядку дорівнює нулю. На практиці часто трапляються ситуації, наприклад, через втрату деяких даних під час деяких прогонів або інші обмеження, коли стовпці матриці проектування не є повністю ортогональними. Загалом тут діє правило, що чим ортогональніші стовпці, тим кращий проект, тобто тим більше незалежної інформації можна отримати з дизайну щодо відповідних цікавих ефектів. Таким чином, одне з міркувань для вибору стандартних центральних композиційних конструкцій полягає в тому, щоб знайти ортогональні або майже ортогональні конструкції.
Поворотні конструкції. Друге міркування пов’язане з першою вимогою, оскільки воно також має відношення до того, як найкраще отримати максимальну кількість (неупередженої) інформації з дизайну, або, зокрема, з експериментальної області інтересу. Не вдаючись у подробиці (див. Box, Hunter і Hunter, 1978; Box and Draper, 1987, розділи 14; див. також Deming and Morgan, 1993, розділ 13), можна показати, що стандартна помилка для передбачення залежної змінної значення пропорційні:
(1 + f(x)' * (X'X)¨¹ * f(x))**½
де f(x) означає (закодовані) ефекти фактора для відповідної моделі ( f(x) є вектором, f(x)' є транспозицією цього вектора), а X є матрицею плану для експерименту, що is, матриця ефектів кодованого фактора для всіх циклів; X'X**-1 є оберненою матрицею добутку. Демінг і Морган (1993) називають цей вираз нормалізованою невизначеністю ; ця функція також пов'язана з функцією дисперсіїяк визначено Боксом і Дрейпером (1987). Рівень невизначеності у передбаченні значень залежних змінних залежить від мінливості проектних точок та їх коваріації протягом циклів. (Зауважте, що він обернено пропорційний детермінанту X'X ; це питання додатково обговорюється в розділі D- та A-оптимальних планів ).
Справа тут у тому, що, знову ж таки, хочеться вибрати схему, яка витягує найбільше інформації щодо залежної змінної та залишає найменшу кількість невизначеності для передбачення майбутніх значень. З цього випливає, що кількість інформації (або нормалізована інформація згідно з Демінгом і Морганом, 1993) є зворотною нормованій невизначеності.
Для простого 4-серійного ортогонального експерименту, показаного раніше, інформаційна функція дорівнює
I x = 4/(1 + x 1 ² + x 2 ²)
де x 1 і x 2 означають налаштування факторів для факторів A і B відповідно (див. Box and Draper, 1987).
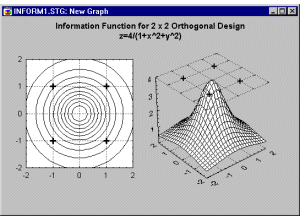
Перевірка цієї функції на графіку (див. вище) показує, що вона постійна на колах з центром у початку координат. Таким чином, будь-який тип обертання вихідних точок проектування генеруватиме однакову кількість інформації, тобто генеруватиме ту саму інформаційну функцію. Таким чином, ортогональний дизайн 2 на 2 у 4 прогонах, показаний раніше, називається поворотним .
Як зазначалося раніше, щоб оцінити другий порядок, квадратичний або нелінійний компонент зв’язку між фактором і залежною змінною, потрібні принаймні 3 рівні для відповідних факторів. Як виглядає інформаційна функція для простого факторного плану 3 на 3 для квадратичної моделі другого порядку, як показано на початку цього розділу?
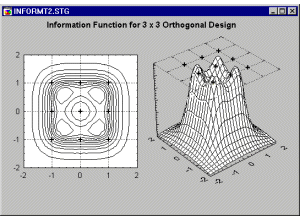
Як виявилося (див. Box and Draper, 1987 та Montgomery, 1991; зверніться також до посібника), ця функція виглядає складнішою, містить «кишені» інформації високої щільності по краях (які, ймовірно, не становлять особливого інтересу для експериментатор), і, очевидно, він не є постійним на колах навколо початку координат. Таким чином, він не обертається, тобто різні повороти проектних точок отримають різну кількість інформації з експериментальної області.
Зіркоподібні та поворотні конструкції другого порядку. Можна показати, що шляхом додавання так званих зіркових точок до простих (квадратних або кубичних) 2-рівневих факторних точок проектування можна отримати поворотні, а часто ортогональні або майже ортогональні плани. Наприклад, якщо додати до простого ортогонального дизайну 2 на 2, показаного раніше, наступні пункти, ви отримаєте поворотний дизайн.
| А | Б | |
|---|---|---|
| Біг 1 Біг 2 Біг 3 Біг 4 Біг 5 Біг 6 Біг 7 Біг 7 Біг 8 Біг 9 Біг 10 |
1 1 -1 -1 -1,414 1,414 0 0 0 0 |
1 -1 1 -1 0 0 -1,414 1,414 0 0 |
Перші чотири прогони в цьому дизайні є попередніми точками факторіального плану 2 на 2 (або квадратними точками чи кубічними точками ); Прогони з 5 по 8 є так званими зоряними точками або осьовими точками , а прогони 9 і 10 є центральними точками.
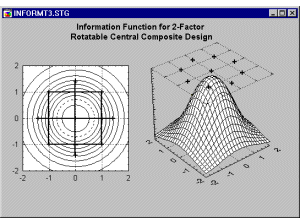
Інформаційна функція для цього плану для моделі другого порядку (квадратичної) є поворотною, тобто постійною на колах навколо початку координат.
Альфа для поворотності та ортогональності
Дві характеристики конструкції, які обговорювалися до цього моменту, — ортогональність і можливість обертання — залежать від кількості центральних точок у конструкції та від так званої осьової відстані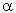 ( альфа ), яка є відстанню зіркових точок від центру конструкції. (тобто 1,414 у дизайні, показаному вище). Можна показати (наприклад, див. Box, Hunter і Hunter, 1978; Box and Draper, 1987, Khuri and Cornell, 1987; Montgomery, 1991), що конструкція обертається, якщо:
( альфа ), яка є відстанню зіркових точок від центру конструкції. (тобто 1,414 у дизайні, показаному вище). Можна показати (наприклад, див. Box, Hunter і Hunter, 1978; Box and Draper, 1987, Khuri and Cornell, 1987; Montgomery, 1991), що конструкція обертається, якщо:
 = ( n c ) ¼
= ( n c ) ¼
де n c означає кількість точок куба в плані (тобто точок у факторіальній частині плану).
Центральна композиційна конструкція є ортогональною, якщо вибрано осьову відстань так, щоб:
= {[( n c + n s + n 0 ) ½ - n c ½ ]² * n c /4} ¼
де
n c – кількість точок куба в дизайні
n s – кількість зіркових точок у дизайні
n 0 – кількість центральних точок у дизайні
Щоб зробити конструкцію одночасно (приблизно) ортогональною та придатною для обертання, потрібно спочатку вибрати осьову відстань для можливості обертання, а потім додати центральні точки (див. Kkuri and Cornell, 1987), щоб:
n 0  4*n c ½ + 4 - 2k
4*n c ½ + 4 - 2k
де k означає кількість факторів у проекті.
Нарешті, якщо бере участь блокування, Бокс і Дрейпер (1987) наводять таку формулу для обчислення осьової відстані для досягнення ортогонального блокування, а в більшості випадків також розумних контурів інформаційної функції, тобто контурів, близьких до сферичних:
= [k*(l+n s0 /n s )/(1+n c0 /n c )] ½
де
n s0 — кількість центральних точок у зірковій частині дизайну
n s — кількість нецентральних зіркових точок у дизайні
n c0 — кількість центральних точок у кубічній частині дизайну
n c — число нецентральних точок куба в дизайні
Доступні стандартні конструкції
Стандартні центральні композиційні дизайни зазвичай складаються з дизайну 2**(kp) для кубічної частини дизайну, яка доповнена центральними точками та точками зірок. Бокс і Дрейпер (1987) перераховують ряд таких дизайнів.
Маленькі композитні конструкції. У стандартних конструкціях кубічна частина дизайну зазвичай має роздільну здатність V (або вище). Це, однак, не є необхідним, і у випадках, коли експериментальні прогони є дорогими, або коли немає необхідності виконувати статистично потужний тест на адекватність моделі, тоді можна вибрати дизайн кубічної частини роздільної здатності III. Наприклад, його можна сконструювати з сильно фракціонованих конструкцій Плакетта-Бермана . Хартлі (1959) описав такі конструкції.
Аналіз центральних композиційних конструкцій
Аналіз центральних композитних планів відбувається приблизно так само, як і для аналізу планів 3**(kp) . Ви підбираєте до даних загальну модель, описану вище; наприклад, для двох змінних ви б відповідали моделі:
y = b 0 + b 1 *x 1 + b 2 *x 2 + b 12 *x 1 *x 2 + b 11 *x 1 2 + b 22 *x 2 2
Пристосована поверхня відгуку
Форму підігнаної загальної реакції найкраще можна підсумувати на графіках, і ви можете створити як контурні графіки, так і графіки поверхні відгуку (див. приклади нижче) для підігнаної моделі.
Категоризовані поверхні відгуку
Ви можете адаптувати 3D-поверхні до своїх даних, класифікованих за іншою змінною. Наприклад, якщо ви скопіювали стандартну центральну композитну конструкцію 4 рази, може бути дуже інформативно побачити, наскільки схожими є поверхні, підігнані до кожної копії.
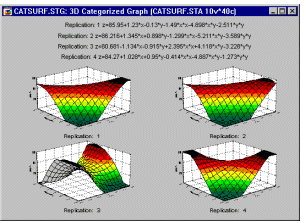
Це дасть вам графічну індикацію надійності результатів і того, де (наприклад, у якій частині поверхні) відбуваються відхилення.
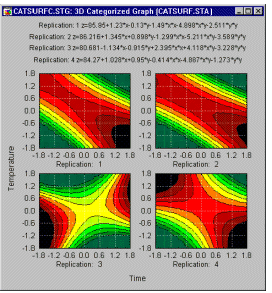
Очевидно, що третя реплікація створила іншу поверхню. У копіях 1 , 2 і 4 підігнані поверхні дуже схожі одна на одну. Таким чином, слід дослідити, що могло спричинити цю помітну різницю в третій копії дизайну.
| Індексувати |
Схеми латинського квадрата (термін « латинський квадрат » вперше використав Ейлер у 1782 р.) використовуються, коли цікаві фактори мають більше двох рівнів і ви заздалегідь знаєте, що взаємодій немає (або вони є незначними).між факторами. Наприклад, якщо ви бажаєте дослідити вплив 4 паливних присадок на зменшення оксидів азоту та маєте у своєму розпорядженні 4 автомобілі та 4 водіїв, тоді ви, звичайно, можете запустити повний факторний план 4 x 4 x 4, що дасть 64 експериментальні запуски. Однак вас насправді не цікавлять будь-які (незначні) взаємодії між добавками до палива та водіями, добавками до палива та автомобілями або автомобілями та водіями. Ви переважно зацікавлені в оцінці основних ефектів, зокрема для фактора добавок до палива. У той же час ви хочете переконатися, що основні ефекти для водіїв і автомобілів не впливають (зміщують) на вашу оцінку основного ефекту добавки до палива.
Якщо ви позначили добавки літерами A, B, C і D, схема латинського квадрата, яка дозволила б вам отримати однозначні оцінки основних ефектів, можна було б підсумувати наступним чином (див. також Box, Hunter і Hunter, 1978, сторінка 263). ):
| автомобіль | ||||
|---|---|---|---|---|
| Водій | 1 | 2 | 3 | 4 |
| 1 2 3 4 |
A D B C |
Б В Г А |
D A C B |
C B A D |
Наведений вище приклад насправді є лише одним із трьох можливих варіантів оцінки ефекту. Ці «композиції» ще називають латинським квадратом . Наведений вище приклад являє собою латинський квадрат 4 x 4; і замість того, щоб вимагати 64 прогони повного факторіалу, ви можете завершити дослідження лише за 16 прогонів.
Греко-латинська площа. Приємною особливістю латинських квадратів є те, що їх можна накладати, щоб утворити так звані греко-латинські квадрати (цей термін вперше використали Фішер і Єйтс, 1934). Наприклад, такі два латинські квадрати 3 x 3 можна накласти, щоб утворити греко-латинський квадрат:

У отриманому греко-латинському квадратному дизайні ви можете оцінити основні ефекти чотирьох 3-рівневих факторів (фактор рядка, фактор стовпця, латинські літери, грецькі літери) лише за 9 прогонів.
Гіпергреко-латинський квадрат. Для певної кількості рівнів існує більше двох можливих латинських квадратів. Наприклад, існує три можливі розташування 4-рівневих латинських квадратів. Якщо всі три з них накласти, ви отримаєте гіпергрецький латинський квадрат . У цьому плані ви можете оцінити основні ефекти всіх п’яти 4-рівневих факторів лише за 16 прогонів експерименту.
Аналіз дизайну
Аналіз латинських квадратів простий. Крім того, можна створити графіки середніх, щоб допомогти в інтерпретації результатів.
Дуже великі дизайни, випадкові ефекти, незбалансоване вкладення
Зауважте, що існує кілька інших статистичних методів, які також можуть аналізувати ці типи дизайнів; подробиці див. у розділі Методи дисперсійного аналізу . Зокрема, у розділі « Компоненти дисперсії та змішана модель ANOVA/ANCOVA» обговорюються дуже ефективні методи аналізу планів із незбалансованою вкладеністю (коли вкладені фактори мають різну кількість рівнів у межах рівнів факторів, у які вони вкладені), дуже великими вкладеними планами ( наприклад, з більш ніж 200 рівнями в цілому) або ієрархічно вкладені конструкції (з випадковими факторами або без них ).
| Індексувати |
Додатки. Останнім часом методи Тагучі стають все більш популярними. Задокументовані приклади значних покращень якості, які стали результатом впровадження цих методів (див., наприклад, Phadke, 1989; Noori, 1989) додали цікавості серед американських виробників. Фактично, деякі з провідних виробників у цій країні почали використовувати ці методи, як правило, з великим успіхом. Наприклад, AT&T використовує ці методи у виробництві дуже великомасштабних інтегрованих ( VLSI) схеми; Крім того, завдяки цим методам Ford Motor Company значно підвищила якість (Американський інститут постачальників, 1984–1988). Однак у міру того, як деталі цих методів стають більш відомими, починають з’являтися й критичні оцінки (наприклад, Bhote, 1988; Tribus and Szonyi, 1989).
Огляд. Надійні методи проектування Taguchi відрізняються від традиційних процедур контролю якості (див. Контроль якості та аналіз процесу ) і промислових експериментів у різних аспектах. Особливе значення мають:
Функції якості та втрат
Що таке якість. Аналіз Тагучі починається з питання про те, як визначити якість. Непросто сформулювати просте визначення того, що є якістю ; однак, коли ваша нова машина глохне посеред жвавого перехрестя, піддаючи себе та інших автомобілістів ризику, ви знаєте, що ваша машина невисокої якості. Іншими словами, визначення зворотної якості є досить простим: це повна втрата для вас і суспільства через функціональні варіації та шкідливі побічні ефекти, пов’язані з відповідним продуктом. Таким чином, як операційне визначення, ви можете вимірювати якість у термінах цієї втрати, і чим більша втрата якості, тим нижча якість.
Розривна (ступінчаста) функція втрат. Можна сформулювати гіпотези про загальний характер і форму функції втрат. Припустимо конкретну ідеальну точку найвищої якості; наприклад, ідеальний автомобіль без проблем з якістю. У статистичному контролі процесу ( SPC; див. також Аналіз процесу ) прийнято визначати допуски навколо номінальної ідеальної точки виробничого процесу. Згідно з традиційною точкою зору, яка передбачається звичайними методами SPC, якщо ви перебуваєте в межах виробничих допусків, у вас не буде проблем. Іншими словами, в межах допуску втрата якості дорівнює нулю; коли ви виходите за межі допусків, втрата якості оголошується неприйнятною. Таким чином, згідно з традиційними поглядами, функція втрати якості є aфункція переривчастого кроку : поки ви перебуваєте в межах допуску, втрата якості незначна; коли ви виходите за межі цих допусків, втрата якості стає неприйнятною.
Квадратична функція втрат. Чи ступінчаста функція, яка передбачається звичайними методами SPC, є хорошою моделлю втрати якості? Повернемося до прикладу «ідеального автомобіля». Чи є різниця між автомобілем, який протягом року після покупки нічого не маєне так, і в машині виникають незначні хрипи, відпадає кілька кріплень і ламається годинник на приладовій панелі (усі гарантійні ремонти, зауважте...)? Якщо ви коли-небудь купували новий автомобіль останнього типу, ви добре знаєте, як можуть дратувати ці, за загальним визнанням, незначні проблеми з якістю. Справа в тому, що нереалістично припустити, що коли ви відходите від номінальних специфікацій у своєму виробничому процесі, втрата якості дорівнює нулю, доки ви залишаєтесь у встановлених межах допуску. Швидше, якщо ви не досягнете точної мети, це призведе до втрат, наприклад, з точки зору задоволеності клієнтів. Крім того, ця втрата, ймовірно, не є лінійною функцією відхилення від номінальних характеристик, а скоріше квадратичною функцією (обернена U). Брязкіт в одному місці у вашій новій машині дратує, але ви, ймовірно, не будете надто засмучуватися через це; додайте ще дві брязкальця, і ви можете оголосити машину "мотлохом". Поступові відхилення від номінальних характеристик призводять не до пропорційного збільшення втрат, а до квадратичного збільшення.
Висновок: контроль мінливості. Якщо фактично втрата якості є квадратичною функцією відхилення від номінального значення, то метою ваших зусиль щодо покращення якості має бути мінімізація квадратів відхилень або дисперсії продукту навколо номінальних (ідеальних) характеристик, а не числа одиниць у межах специфікації (як це робиться в традиційних процедурах SPC).
Співвідношення сигнал/шум (S/N).
Вимірювання втрати якості. Навіть якщо ви дійшли висновку, що функція втрати якості, ймовірно, має квадратичний характер, ви все ще не знаєте, як точно виміряти втрату якості. Однак ви знаєте, що який би показник ви не вибрали, він повинен відображати квадратичну природу функції.
Фактори сигналу, шуму та керування. Продукт ідеальної якості повинен завжди однаково реагувати на сигналинадані користувачем. Коли ви повертаєте ключ у замку запалювання вашого автомобіля, ви очікуєте, що стартер закрутиться і двигун запуститься. В автомобілі ідеальної якості процес запуску відбувався б завжди однаково - наприклад, після трьох оборотів стартера двигун оживає. Якщо у відповідь на той самий сигнал (поворот ключа запалювання) у цьому процесі виникає випадкова змінність, то у вас якість не ідеальна. Наприклад, через такі неконтрольовані фактори, як сильний холод, вологість, зношеність двигуна тощо, двигун іноді може запускатися лише після 20 переворотів і врешті не запускатися взагалі. Цей приклад ілюструє ключовий принцип вимірювання якості за Тагучі: ви хочете звести до мінімуму мінливість продуктивності продукту у відповідь на шум .факторів, максимізуючи варіабельність у відповідь на сигнальні фактори.
Фактори шуму - це ті, які не знаходяться під контролем оператора продукту. У прикладі з автомобілем ці фактори включають зміни температури, різну якість бензину, знос двигуна тощо. Фактори сигналу – це ті фактори, які встановлює або контролює оператор виробу для використання його призначених функцій (поворот ключа запалювання в положення заводити машину).
Нарешті, мета ваших зусиль щодо покращення якості полягає в тому, щоб знайти найкращі налаштування факторів під вашим контролем , які беруть участь у виробничому процесі, щоб максимізувати співвідношення S/N; таким чином, фактори в експерименті являють собою контрольні фактори.
Співвідношення S/N. Висновок попереднього абзацу полягає в тому, що якість можна кількісно оцінити в термінах відповіді відповідного продукту на фактори шуму та сигналу. Ідеальний продукт реагуватиме лише на сигнали оператора і на нього не впливатимуть випадкові шумові фактори (погода, температура, вологість тощо). Тому метою ваших зусиль щодо покращення якості можна назвати спробу максимізувати співвідношення сигнал/шум (S/N) для відповідного продукту. Співвідношення S/N, описані в наступних параграфах, були запропоновані Taguchi (1987).
Чим менше, тим краще. У випадках, коли ви хочете звести до мінімуму появу деяких небажаних характеристик продукту, вам слід обчислити таке співвідношення S/N:
Eta = -10 * log 10 [(1/n) *  (y i 2 )] для i = 1 до ні. vars
див. зовнішні масиви
(y i 2 )] для i = 1 до ні. vars
див. зовнішні масиви
Тут Eta — результуюче співвідношення S/N; n — кількість спостережень за конкретним продуктом, а y — відповідна характеристика. Наприклад, кількість недоліків у фарбі на автомобілі можна виміряти як змінну y та проаналізувати через це співвідношення S/N. Вплив сигнальних факторів дорівнює нулю, оскільки нуль недоліків - це єдиний передбачуваний або бажаний стан фарби на автомобілі. Зверніть увагу, як це співвідношення S/N є вираженням припущеної квадратичної природи функції втрат. Фактор 10гарантує, що цей коефіцієнт вимірює зворотний показник "поганої якості"; чим більше дефектів у фарбі, тим більшою є сума квадратів числа дефектів і тим менше (тобто негативніше) співвідношення S/N. Таким чином, максимізація цього співвідношення підвищить якість.
Номінально-найкращий. Тут у вас є фіксоване значення сигналу (номінальне значення), і дисперсію навколо цього значення можна вважати результатом факторів шуму:
Eta = 10 * log 10 (середнє значення 2 /відхилення)
Це відношення сигнал/шум можна використовувати, коли ідеальна якість прирівнюється до конкретного номінального значення. Наприклад, розмір поршневих кілець для автомобільного двигуна повинен бути максимально наближеним до специфікації, щоб забезпечити високу якість.
Чим більше, тим краще. Прикладами такого типу інженерної проблеми є економія палива (милі на галон) автомобіля, міцність бетону, стійкість екрануючих матеріалів тощо. Слід використовувати наступне співвідношення S/N:
Eta = -10 * log 10 [(1/n) * (1/y i 2 )] для i = 1 до ні. vars
див. зовнішні масиви
Підписана ціль. Цей тип відношення S/N підходить, коли характеристика якості, що цікавить, має ідеальне значення 0 (нуль), і можуть мати місце як позитивні, так і негативні значення характеристики якості. Наприклад, напруга зміщення постійного струму диференціального операційного підсилювача може бути позитивною або негативною (див. Phadke, 1989). Для цих типів проблем слід використовувати таке співвідношення S/N:
Eta = -10 * log 10 (с 2 ) для i = 1 до ні. vars див. зовнішні масиви
де s 2 означає дисперсію характеристики якості за вимірюваннями (змінними).Фракція дефектна. Це співвідношення S/N є корисним для мінімізації браку, мінімізації відсотка пацієнтів, у яких розвиваються побічні ефекти ліків, тощо. Тагучі також називає результуючі значення Eta Омегами; зауважте, що це співвідношення S/N ідентичне знайомому логіт-перетворенню (див. також Нелінійне оцінювання ):
Eta = -10 * log 10 [p/(1-p)]
де
p – частка дефекту
Упорядковані категорії (аналіз накопичення). У деяких випадках вимірювання характеристики якості можна отримати лише за допомогою категоричних суджень. Наприклад, споживачі можуть оцінити продукт як відмінний, хороший, середній або нижче середнього . У такому випадку ви спробуєте максимізувати кількість відмінних чи добрих оцінок. Як правило, результати аналізу накопичення підсумовуються графічно на стовпчастій діаграмі.
Ортогональні масиви
Третій аспект надійних методів проектування Тагучі найбільш схожий на традиційні методи. Тагучі розробив систему табличних планів (масивів), які дозволяють оцінити максимальну кількість основних ефектів незміщеним (ортогональним) способом з мінімальною кількістю прогонів в експерименті. Латинський квадрат , дизайн 2**(kp) ( зокрема, дизайн Плакетта-Бермана ) і основний дизайн Бокса-Бенкена також спрямовані на досягнення цієї мети. Насправді багато стандартних ортогональних масивів, зведених у таблиці Тагучі, ідентичні дробовим дворівневим факторіалам, планам Плакетта-Бермана, планам Бокса-Бенкена, латинському квадрату, греко-латинським квадратам тощо.
Аналіз дизайнів
Більшість аналізів надійних експериментів проектування зводяться до стандартного дисперсійного аналізу відповідних співвідношень S/N, ігноруючи двосторонню взаємодію чи взаємодію вищого порядку . Однак при оцінці дисперсії помилок зазвичай об’єднують основні ефекти незначного розміру.
Аналіз співвідношення S/N у стандартних конструкціях. На цьому етапі слід зазначити, що, звісно, усі схеми, які обговорювалися до цього моменту (наприклад, 2**(kp), 3**(kp) , змішані факторіали рівня 2 та 3, латинські квадрати , центральний композит designs ) можна використовувати для аналізу обчисленого вами співвідношення S/N. Фактично, багато додаткових діагностичних графіків та інших опцій, доступних для цих проектів (наприклад, оцінка квадратичних компонентів тощо), можуть виявитися дуже корисними під час аналізу мінливості (співвідношення S/N) у виробничому процесі.
Сюжет засобів. Візуальним підсумком експерименту є графік середнього Eta (відношення S/N) за рівнями факторів. На цьому графіку можна легко визначити оптимальне налаштування (тобто найбільше співвідношення S/N) для кожного фактора.
Перевірочні досліди. Для цілей передбачення ви можете обчислити очікуване співвідношення S/N, враховуючи визначену користувачем комбінацію налаштувань факторів (ігноруючи фактори, які були об’єднані в термін помилки). Ці передбачені співвідношення сигнал/шум потім можна використовувати в експерименті перевірки, де інженер фактично налаштовує машину відповідним чином і порівнює отримане спостережене співвідношення сигнал/шум із прогнозованим співвідношенням сигнал/шум з експерименту. Якщо виникають значні відхилення, слід зробити висновок, що проста модель основного ефекту не підходить.
У таких випадках Тагучі (1987) рекомендує трансформувати залежну змінну, щоб досягти адитивності факторів, тобто «зробити» модель основних ефектів відповідною. Phadke (1989, Розділ 6) також детально обговорює методи досягнення адитивності факторів.
Аналіз накопичення
При аналізі впорядкованих категоричних даних ANOVA не підходить. Натомість ви створюєте кумулятивний графік кількості спостережень у певній категорії. Для кожного рівня кожного фактора ви будуєте графік сукупної частки кількості дефектів. Таким чином, цей графік надає цінну інформацію щодо розподілу категорійних підрахунків між різними налаштуваннями факторів.
Резюме
Коротко підводячи підсумок, при використанні методів Тагучі спочатку потрібно визначити конструкторські або контрольні фактори, які можуть бути встановлені дизайнером або інженером. Це фактори в експерименті, для яких ви спробуєте різні рівні. Далі ви вирішуєте вибрати відповідний ортогональний масив для експерименту. Далі вам потрібно вирішити, як виміряти цікаву характеристику якості. Пам’ятайте, що більшість співвідношень S/N вимагають проведення кількох вимірювань під час кожного циклу експерименту; наприклад, мінливість навколо номінального значення неможливо інакше оцінити. Нарешті, ви проводите експеримент і визначаєте фактори, які найбільш сильно впливають на вибране співвідношення S/N, і відповідно скидаєте свою машину або виробничий процес.
| Індексувати |
Особливі проблеми виникають під час аналізу сумішей компонентів, сума яких має бути константою. Наприклад, якщо ви хочете оптимізувати смак фруктового пуншу, що складається з соків 5 фруктів, то сума пропорцій усіх соків у кожній суміші має бути 100%. Таким чином, завдання оптимізації сумішей зазвичай виникає в харчовій промисловості, нафтопереробці або виробництві хімічних речовин. Було розроблено ряд проектів, спрямованих саме на аналіз і моделювання сумішей (див., наприклад, Корнелл, 1990a, 1990b; Корнелл і Хурі, 1987; Демінг і Морган, 1993; Монтгомері, 1991).
Трикутні координати
Загальний спосіб, у який можна узагальнити пропорції суміші, — це трикутні (трикутні) графіки. Наприклад, припустимо, що у вас є суміш, яка складається з 3 компонентів A, B і C. Будь-яка суміш трьох компонентів може бути підсумована точкою в трикутній системі координат, що визначається трьома змінними.
Наприклад, візьмемо наступні 6 різних сумішей 3 компонентів.
| А | Б | C |
|---|---|---|
| 1 0 0 0,5 0,5 0 |
0 1 0 0,5 0 0,5 |
0 0 1 0 0,5 0,5 |
Сума для кожної суміші дорівнює 1,0, тому значення для компонентів у кожній суміші можна інтерпретувати як пропорції. Якщо ви побудуєте ці дані на звичайній тривимірній діаграмі розсіювання, стане очевидним, що точки утворюють трикутник у тривимірному просторі. Тільки точки всередині трикутника, де сума значень компонентів дорівнює 1, є дійсними сумішами. Тому можна просто побудувати лише трикутник, щоб підсумувати значення компонентів (пропорції) для кожної суміші.
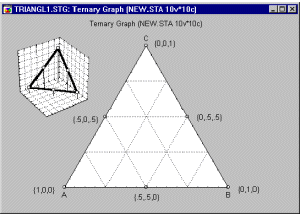
Щоб зчитати координати точки на трикутному графіку, ви повинні просто «опустити» лінію від кожної відповідної вершини до сторони трикутника нижче.
У вершині для конкретного фактора є чиста суміш, тобто така, яка містить лише відповідний компонент. Таким чином, координати точки вершини дорівнюють 1 (або 100% , або як би інакше суміші масштабувалися) для відповідного компонента та 0 (нуль) для всіх інших компонентів. На стороні, протилежній відповідній вершині, значення для відповідного компонента дорівнює 0 (нуль) і 0,5 (або 50% тощо) для інших компонентів.
Трикутні поверхні та контури
Тепер можна додати до трикутника четвертий вимір, який є перпендикулярним до перших трьох. Використовуючи цей розмір, можна побудувати графік значень залежної змінної або функції (поверхні), яка відповідає залежній змінній. Зауважте, що поверхня реакції може бути показана у 3D, де прогнозована відповідь ( оцінка смаку ) вказується відстанню поверхні від трикутної площини, або її можна вказати на контурній діаграмі, де нанесено контури постійної висоти. на 2D трикутнику.
Тут слід зазначити, що ви можете створювати категоризовані потрійні графи. Це дуже корисно, тому що вони дозволяють підігнати до залежної змінної (наприклад, смаку) поверхню відгуку для різних рівнів четвертого компонента.
Канонічна форма поліномів суміші
Підгонка поверхні відгуку до даних суміші, в принципі, виконується так само, як підгонка поверхонь до, наприклад, даних центральних композитних проектів . Однак існує проблема, що дані суміші обмежені, тобто сума значень усіх компонентів має бути постійною.
Розглянемо простий випадок двох факторів A і B . Хтось може захотіти підібрати просту лінійну модель:
y = b 0 + b A *x A + b B *x B
Тут y позначає значення залежної змінної, b A і b B позначає коефіцієнти регресії, x A і x B позначає значення факторів. Припустимо, що сума x A і x B повинна дорівнювати 1; ви можете помножити b 0 на 1=(x A + x B ) :
y = (b 0 *x A + b 0 *x B ) + b A *x A + b B *x B
або:
y = b' A *x A + b' B *x B
де b' A = b 0 + b A і b' B = b 0 + b B . Таким чином, оцінка цієї моделі зводиться до підгонки моделі множинної регресії без перехоплення. (Див. також Множинна регресія , щоб дізнатися більше про множинну регресію.)
Загальні моделі для даних суміші
Квадратичну та кубічну моделі можна подібним чином спростити (як показано для простої лінійної моделі вище), утворюючи чотири стандартні моделі, які зазвичай відповідають даним суміші. Ось формули для випадку 3 змінних для цих моделей (див. Корнелл, 1990, для додаткових деталей).
Лінійна модель :
y = b 1 *x 1 + b 2 *x 2 + b 3 *x 3
Квадратична модель :
y = b 1 *x 1 + b 2 *x 2 + b 3 *x 3 + b 12 *x 1 *x 2 + b 13 *x 1 *x 3 + b 23 *x 2 *x 3
Спеціальна кубічна модель :
y = b 1 *x 1 + b 2 *x 2 + b 3 *x 3 + b 12 *x 1 *x 2 + b 13 *x 1 *x 3 + b 23 *x 2 *x 3 + b 123 * х 1 *х 2 *х 3
Повна кубічна модель :
y = b 1 *x 1 + b 2 *x 2 + b 3 *x 3 + b 12 *x 1 *x 2 + b 13 *x 1 *x 3 + b 23 *x 2 *x 3 + d 12 * x 1 *x 2 *(x 1 - x 2 ) + d 13 *x 1 *x 3 *(x 1 - x 3 ) + d 23 *x 2 *x 3*(x 2 - x 3 ) + b 123 *x 1 *x 2 *x 3
(Зауважте, що d ij також є параметрами моделі.)
Стандартні проекти для експериментів із сумішшю
Для експериментів із сумішами зазвичай використовуються два різних типи стандартних конструкцій. Обидва вони оцінюватимуть трикутну поверхню відгуку у вершинах (тобто кутах трикутника) і центроїдах (сторонах трикутника). Іноді ці конструкції доповнюються додатковими внутрішніми елементами.
Симплексно-решітчасті конструкції. У такому розташуванні проектних точок перевіряється m+1 рівновіддалених пропорцій для кожного фактора або компонента в моделі:
x i = 0, 1/m, 2/m, ..., 1 i = 1,2,...,q
і перевіряються всі комбінації рівнів факторів. Отриманий дизайн називається {q,m} симплексною решіткою . Наприклад, схема симплексної решітки {q=3, m=2} включатиме такі суміші:
| А | Б | C |
|---|---|---|
| 1 0 0 .5 .5 0 |
0 1 0 .5 0 .5 |
0 0 1 0 .5 .5 |
Схема симплексної решітки {q=3,m=3} включатиме точки:
| А | Б | C |
|---|---|---|
| 1 0 0 1/3 1/3 0 2/3 2/3 0 1/3 |
0 1 0 2/3 0 1/3 1/3 0 2/3 1/3 |
0 0 1 0 2/3 2/3 0 1/3 1/3 1/3 |
Симплексно-центроїдні конструкції. Альтернативним розташуванням налаштувань, представленим Шеффом (1963), є так званий симплекс-центроїд . Тут точки проектування відповідають усім перестановкам чистих сумішей (наприклад, 1 0 0; 0 1 0; 0 0 1 ), перестановкам бінарних сумішей ( � � 0; � 0 �; 0 � � ), перестановкам сумішей із трьох компонентів тощо. Наприклад, для 3 факторів схема симплексного центроїда складається з точок:
| А | Б | C |
|---|---|---|
| 1 0 0 1/2 1/2 0 1/3 |
0 1 0 1/2 0 1/2 1/3 |
0 0 1 0 1/2 1/2 1/3 |
Додавання внутрішніх точок. Ці малюнки іноді доповнюються внутрішніми точками (див. Khuri and Cornell, 1987, стор. 343; Mason, Gunst, Hess; 1989; стор. 230). Наприклад, для 3 факторів можна додати внутрішні точки:
| А | Б | C |
|---|---|---|
| 2/3 1/6 1/6 |
1/6 2/3 1/6 |
1/6 1/6 2/3 |
Якщо нанести ці точки на діаграму розсіювання з трикутними координатами; можна побачити, як ці конструкції рівномірно покривають експериментальну область, визначену трикутником.
Нижні обмеження
Описані вище дизайни вимагають вершинних точок, тобто чистих сумішей, що складаються лише з одного інгредієнта. На практиці ці пункти часто можуть бути недійсними, тобто чисті суміші не можуть бути виготовлені через вартість або інші обмеження. Наприклад, припустімо, що ви хочете вивчити вплив харчової добавки на смак фруктового пуншу. Додатковий інгредієнт можна змінювати лише в невеликих межах, наприклад, він не може перевищувати певного відсотка від загальної кількості. Очевидно, що фруктовий пунш, який є чистою сумішшю, що складається лише з добавок, взагалі не буде фруктовим пуншем або, що ще гірше, може бути токсичним. Ці типи обмежень дуже поширені в багатьох застосуваннях експериментів із сумішшю.
Розглянемо 3-компонентний приклад, де компонент A обмежений таким чином, що x A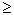 .3 . Загальна сума 3-компонентної суміші має дорівнювати 1. Це обмеження можна візуалізувати на трикутному графіку лінією в трикутній координаті для x A =.3 , тобто лінією, яка є паралельною протилежному краю трикутника до точки A вершини.
.3 . Загальна сума 3-компонентної суміші має дорівнювати 1. Це обмеження можна візуалізувати на трикутному графіку лінією в трикутній координаті для x A =.3 , тобто лінією, яка є паралельною протилежному краю трикутника до точки A вершини.
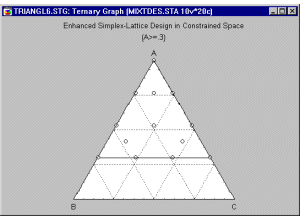
Тепер можна побудувати дизайн, як і раніше, за винятком того, що одна сторона трикутника визначається обмеженням. Пізніше, під час аналізу, можна переглянути оцінки параметрів для так званих псевдокомпонентів , розглядаючи обмежений трикутник як повний трикутник.
Кілька обмежень. Кілька нижніх обмежень можна розглядати аналогічно, тобто ви можете побудувати підтрикутник у повному трикутнику, а потім розмістити точки проекту в цьому підтрикутнику відповідно до вибраного проекту.
Верхнє та нижнє обмеження
Коли є як верхні, так і нижні обмеження (як це часто буває в експериментах із сумішами), тоді стандартні плани симплексної решітки та симплексного центроїда більше не можуть бути побудовані, оскільки підобласть, визначена обмеженнями, більше не є трикутником. Існує загальний алгоритм для знаходження точок вершини та центроїда для таких обмежених планів .
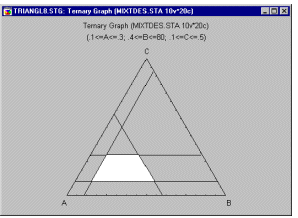
Зауважте, що ви все ще можете аналізувати такі проекти, підганяючи стандартні моделі до даних.
Аналіз експериментів із сумішшю
Аналіз експериментів зі сумішшю зводиться до множинної регресії з нульовим відрізком. Як пояснювалося раніше, обмеження суміші – сума всіх компонентів має бути сталою – може бути враховано шляхом підгонки множинних регресійних моделей, які не включають перехоплюваний член. Якщо ви не знайомі з множинною регресією, ви можете переглянути на цьому етапі множинну регресію .
Конкретні моделі, які зазвичай розглядаються, були описані раніше. Підводячи підсумок, можна підходити до залежних змінних поверхонь відгуку зростаючої складності, тобто, починаючи з лінійної моделі, потім квадратичної моделі, спеціальної кубічної моделі та повної кубічної моделі. Нижче наведено таблицю з кількістю термінів або параметрів у кожній моделі для вибраної кількості компонентів (див. також Таблицю 4, Cornell, 1990):
| Модель (ступінь полінома) | ||||
|---|---|---|---|---|
| № комп. |
Лінійний |
Quadr. |
Спеціальний куб |
Повний куб |
| 2 3 4 5 6 7 8 |
2 3 4 5 6 7 8 |
3 6 10 15 21 28 36 |
-- 7 14 25 41 63 92 |
-- 10 20 35 56 84 120 |
Дисперсійний аналіз
Щоб вирішити, яка з моделей зростаючої складності забезпечує достатньо хорошу відповідність спостережуваним даним, зазвичай порівнюють моделі в ієрархічному, поетапному порядку. Наприклад, розглянемо 3-компонентну суміш, до якої була встановлена повна кубічна модель.
| ANOVA; Вар.:DV (mixt4.sta) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 3 Конструкція суміші факторів; Загальна кількість суміші=1., 14 прогонів. Послідовна підгонка моделей зростаючої складності |
||||||||||
| Модель |
Ефект СС |
df Ефект |
Ефект MS |
Помилка SS |
df Помилка |
Помилка MS |
Ф |
стор |
Р-кв |
R-sqr Adj. |
| Лінійний квадратичний спеціальний кубічний кубічний підсумок скоригований |
44,755 30,558 ,719 8,229 91,627 |
2 3 1 3 13 |
22,378 10,186 , 719 2,743 7,048 |
46,872 16,314 15,596 7,367 |
11 8 7 4 |
4,2611 2,0393 2,2279 1,8417 |
5,2516 4,9949 ,3225 1,4893 |
.0251 .0307 .5878 .3452 |
.4884 .8220 .8298 .9196 |
.3954 .7107 .6839 .7387 |
По-перше, лінійна модель була підігнана до даних. Незважаючи на те, що ця модель має 3 параметри, по одному для кожного компонента, ця модель має лише 2 ступені свободи. Це відбувається через загальне обмеження суміші, що сума всіх значень компонентів є постійною. Одночасний тест для всіх параметрів цієї моделі є статистично значущим (F(2,11)=5,25; p<0,05) . Додавання 3 квадратичних параметрів моделі ( b 12 *x 1 *x 2 , b 13 *x 1 *x 3 , b 23 *x 2 *x 3 ) додатково значно покращує відповідність моделі (F(3,8 )=4,99; p<0,05). Однак додавання параметрів для спеціальної кубічної та кубічної моделей суттєво не покращує прилягання поверхні. Таким чином, можна зробити висновок, що квадратична модель забезпечує адекватну відповідність даним (звичайно, в очікуванні подальшої перевірки залишків на викиди тощо).
R-квадрат. Значення R-квадрат можна інтерпретувати як частку мінливості навколо середнього для залежної змінної, яку можна врахувати відповідною моделлю. (Зауважте, що для моделей без перехоплення деякі програми множинної регресії обчислюють лише значення R-квадрата , що стосується частки дисперсії навколо 0 (нуля), що враховується незалежними змінними; для отримання додаткової інформації див. Kvalseth, 1985; Okunade, Чанг і Еванс, 1993 р.)
Чиста помилка та невідповідність. Корисність оцінки чистої похибки для оцінки загальної невідповідності обговорювалася в контексті центральних складених планів . Якщо деякі прогони в дизайні були репліковані, тоді можна обчислити оцінку мінливості помилок, засновану лише на мінливості між реплікованими прогонами. Ця мінливість є хорошим показником ненадійності вимірювань, незалежно від моделі, яка була підібрана для даних, оскільки вона базується на ідентичних налаштуваннях факторів (або сумішах у цьому випадку). Можна перевірити залишкову мінливість після підгонки поточної моделі до цієї оцінки чистої помилки. Якщо цей тест є статистично значущим, тобто якщо залишкова мінливість є значно більшою, ніж мінливість чистої помилки, тоді можна зробити висновок, що, швидше за все, існують додаткові суттєві відмінності між сумішами, які не можуть бути враховані поточною моделлю. Таким чином, можлива загальна невідповідність поточної моделі. У такому випадку спробуйте більш складну модель, можливо, лише додавши окремі члени наступної моделі вищого порядку (наприклад, лише b 13 *x 1 *x 3 до лінійної моделі).
Оцінки параметрів
Зазвичай після підгонки конкретної моделі слід переглядати оцінки параметрів. Пам’ятайте, що лінійні члени в моделях суміші обмежені, тобто сума компонентів має бути постійною. Отже, незалежні тести статистичної значущості для лінійних компонентів не можуть бути виконані.
Псевдокомпоненти
Щоб забезпечити незалежне від масштабу порівняння оцінок параметрів, під час аналізу налаштування компонентів зазвичай перекодуються в так звані псевдокомпоненти, щоб (див. також Корнелл, 1993, Розділ 3):
x' i = (x i -L i )/(Загальний-L)
Тут x' i позначає i 'ту псевдокомпоненту, x i позначає початкове значення компонента, L i позначає нижнє обмеження (ліміт) для i 'ї складової, L позначає суму всіх нижніх обмежень (ліміти) для всіх компонентів у проекті, а загальна сума – це загальна суміш.
Питання нижчих обмежень також обговорювалося раніше в цьому розділі. Якщо проект є стандартною симплекс-решіткою або симплекс-центроїдом (див. вище), то це перетворення зводиться до зміни масштабу факторів таким чином, щоб утворити підтрикутник (підсимплекс), як визначено нижніми обмеженнями. Однак ви можете обчислити оцінки параметрів на основі вихідної (нетрансформованої) метрики компонентів експерименту. Якщо ви хочете використовувати підібрані значення параметрів для цілей передбачення (тобто, щоб передбачити значення залежних змінних), то параметри для неперетворених компонентів часто зручніші для використання. Зауважте, що діалогове вікно результатів для експериментів зі сумішшю містить параметри для прогнозування залежної змінної для визначених користувачем значень компонентів у їхній початковій метриці.
Параметри графіка
Поверхневі та контурні епюри. Відповідну встановлену модель можна візуалізувати на трикутних поверхневих графіках або контурних графіках, які, за бажанням, також можуть містити відповідну встановлену функцію.
Зверніть увагу, що підібрана функція, яка відображається на поверхневих і контурних графіках, завжди стосується оцінок параметрів для псевдокомпонентів.
Категоризовані поверхневі ділянки. Якщо ваш проект включає реплікації (і реплікації закодовані у вашому файлі даних), тоді ви можете використовувати тривимірні потрійні графіки , щоб переглянути відповідну відповідність, реплікацію за реплікацією.
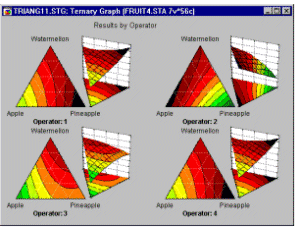
Звичайно, якщо у вашому дослідженні є інші категоріальні змінні (наприклад, оператор або експериментатор; машина тощо), ви також можете класифікувати 3D-графіку поверхні за цими змінними.
Слідові ділянки. Однією з допоміжних засобів для інтерпретації трикутної поверхні відгуку є так званий графік трасування . Припустімо, ви подивилися на контурний графік поверхні відгуку для трьох компонентів. Потім визначте еталонну суміш для двох компонентів, наприклад, утримуйте значення для A і B на рівні 1/3 кожного. Зберігаючи відносні пропорції A і B постійними (тобто рівні пропорції в цьому випадку), ви можете побудувати графік оціненої відповіді (значення для залежної змінної) для різних значень C .
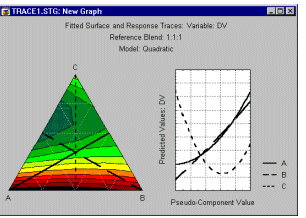
Якщо еталонна суміш для A і B становить 1:1 , то результуюча лінія або реакційний слід є віссю для фактора C ; тобто лінія, що тягнеться з точки вершини C і з’єднується з протилежною стороною трикутника під прямим кутом. Однак також можна створити графіки для інших еталонних сумішей. Як правило, діаграма трасування містить трасування для всіх компонентів, враховуючи поточну еталонну суміш.
Залишкові ділянки. Нарешті, після прийняття рішення про модель важливо переглянути прогнозні залишки, щоб визначити викиди або області невідповідності. Крім того, слід переглянути стандартний графік нормальної ймовірності залишків і діаграму розсіювання спостережуваних і прогнозованих значень. Пам’ятайте, що множинний регресійний аналіз (тобто процес підгонки поверхні) припускає, що залишки розподілені нормально, і слід уважно переглядати залишки на наявність будь-яких явних викидів.
| Індексувати |
Огляд
Як згадувалося в контексті планування сумішей , у реальних дослідженнях часто трапляється, що досліджувана область інтересів обмежена, тобто не всі налаштування факторів можна поєднати з усіма налаштуваннями для інших факторів у дослідженні. Існує алгоритм, запропонований Piepel (1988) і Snee (1985) для знаходження вершин і центроїдів для таких обмежених областей.
Проекти для обмежених експериментальних регіонів
Коли в експерименті з багатьма факторами існують обмеження щодо можливих значень цих факторів та їх комбінацій, незрозуміло, як діяти далі. Розумним підходом є включення в експерименти прогонів у крайніх вершинних точках і точках центроїда обмеженої області, що зазвичай повинно забезпечити добре покриття обмеженої експериментальної області (наприклад, див. Piepel, 1988; Snee, 1975). Насправді схеми змішування, розглянуті в попередньому розділі, надають приклади таких планів, оскільки вони зазвичай побудовані таким чином, щоб включати точки вершини та центроїда обмеженої області, яка складається з трикутника (симплекса).
Лінійні обмеження
Один із загальних способів, за допомогою якого можна узагальнити більшість обмежень, які зустрічаються в експериментах у реальному світі, це лінійне рівняння (див. Piepel, 1988):
A 1 x 1 + A 2 x 2 + ... + A q x q + A 0  0
0
Тут A 0 , .., A q є параметрами для лінійного обмеження на q факторів, а x 1 ,.., x q означає значення факторів (рівні) для q факторів. Ця загальна формула може врахувати навіть дуже складні обмеження. Наприклад, припустимо, що в двофакторному експерименті перший фактор завжди має бути встановлений принаймні вдвічі більшим, ніж другий, тобто x 1 2*x 2 . Це просте обмеження можна переписати як x 1 -2*x 2 0 . Обмеження співвідношення 2*x 1 /x2 1 можна переписати як 2*x 1 - x 2 0 і так далі.
Проблема кількох верхніх і нижніх обмежень на значення компонентів у сумішах обговорювалася раніше в контексті експериментів із сумішами . Наприклад, припустимо, що в трикомпонентній суміші фруктових соків верхнє та нижнє обмеження на компоненти такі (див. приклад 3.2, у Cornell 1993):
40%  кавун (x 1 ) 80%
кавун (x 1 ) 80%
10% ананас (x 2 ) 50%
10% апельсин (x 3 ) 30%
Ці обмеження можна переписати як лінійні обмеження у вигляді:
| кавун: |
x 1 -40 0 -x 1 +80 0 |
| Ананас: |
x 2 -10 0 -x 2 +50 0 |
| Помаранчевий: |
x 3 -10 0 -x 3 +30 0 |
Таким чином, проблема знаходження проектних точок для експериментів суміші з компонентами з кількома верхніми та нижніми обмеженнями є лише окремим випадком загальних лінійних обмежень.
Алгоритм Піпеля і Сні
Для особливого випадку обмежених сумішей такі алгоритми, як алгоритм XVERT (див., наприклад, Корнелл, 1990), часто використовуються для знаходження точок вершини та центроїда обмеженої області (всередині трикутника з трьох компонентів, тетраедра з чотирьох компонентів тощо). Загальний алгоритм, запропонований Piepel (1988) і Snee (1979) для знаходження вершин і центроїдів, може бути застосований як до сумішей, так і до сумішей. Загальний підхід цього алгоритму детально описаний Snee (1979).
Зокрема, він розглядатиме одне за одним кожне обмеження, записане у вигляді лінійного рівняння, як описано вище. Кожне обмеження представляє лінію (або площину), що проходить через експериментальну область. Для кожного наступного обмеження ви оціните, чи перетинає поточне (нове) обмеження поточну дійсну область дизайну. Якщо так, будуть обчислені нові вершини, які визначають нову дійсну експериментальну область, оновлену для останнього обмеження. Потім він перевірить, чи стало будь-яке з раніше оброблених обмежень зайвим, тобто визначити лінії або площини в експериментальній області, які зараз повністю знаходяться за межами дійсної області. Після обробки всіх обмежень він обчислить центроїди для сторін обмеженої області (у порядку, який вимагає користувач). Для двовимірного (двофакторного) випадку можна легко відтворити цей процес, просто провівши лінії через експериментальну область, по одній для кожного обмеження; те, що залишилося, це дійсна експериментальна область.
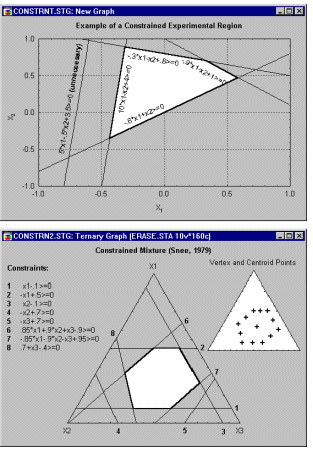
Для отримання додаткової інформації див. Piepel (1988) або Snee (1979).
Вибір точок для експерименту
Після обчислення вершин і центроїдів ви можете зіткнутися з проблемою вибору підмножини точок для експерименту. Якщо кожен експериментальний запуск є дорогим, тоді може бути неможливо просто запустити всі точки вершини та центроїда. Зокрема, коли існує багато факторів і обмежень, кількість центроїдів може швидко стати дуже великою.
Якщо ви перевіряєте велику кількість факторів і не зацікавлені в нелінійних ефектах, тоді вибір лише вершинних точок зазвичай забезпечить гарне покриття експериментальної області. Щоб збільшити статистичну потужність (щоб збільшити ступені свободи для члена помилки ANOVA), ви також можете включити кілька прогонів з факторами, встановленими на загальному центроїді обмеженої області.
Якщо ви розглядаєте кілька різних моделей, які могли б підійти після того, як дані будуть зібрані, тоді ви можете використовувати варіанти D- та A-оптимального дизайну . Ці параметри допоможуть вам вибрати точки проектування, які витягнуть максимальну кількість інформації з обмеженої експериментальної області, враховуючи ваші моделі.
Аналіз дизайнів для обмежених поверхонь і сумішей
Як згадувалося в розділі про центральні композиційні плани та дизайни сумішей , після того, як обмежені точки проектування були обрані для остаточного експерименту, і дані для залежних змінних, що цікавлять, були зібрані, аналіз цих планів може продовжуватися стандартним способом .
Наприклад, Корнелл (1990, сторінка 68) описує експеримент із трьома пластифікаторами та їхній вплив на кінцеву товщину вінілу (для автомобільних сидінь). Обмеження для трьох компонентів пластифікатора x 1 , x 2 і x 3 такі:
.409 x 1.849.000 x 2.252.151 x 3.274
_ _ _
_ _
(Зверніть увагу, що ці значення вже перемасштабовано, тому загальна сума для кожної суміші має дорівнювати 1.) Створені точки вершини та центроїда:
| х 1 | х 2 | х 3 |
|---|---|---|
| .8490 .7260 .4740 .5970 .6615 .7875 .6000 .5355 .7230 |
.0000 .0000 .2520 .2520 .1260 .0000 .1260 .2520 .1260 |
.1510 .2740 .2740 .1510 .2125 .2125 .2740 .2125 .1510 |
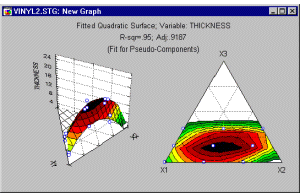
| Індексувати |
Огляд
У розділах про стандартні факторіальні плани (див. 2**(kp) Дробові факторіальні плани та 3**(kp), Box Behnken і змішані факторні плани 2 і 3 рівнів ) і центральні складені плани властивість ортогональності факторних ефектів обговорювалося. Коротше кажучи, коли параметри рівня факторів для двох факторів в експерименті некорельовані, тобто коли вони змінюються незалежно один від одного, тоді вони називаються ортогональними один одному. (Якщо ви знайомі з матричною та векторною алгеброю, два вектори-стовпці X 1 і X 2 у проектній матриці є ортогональними, якщо X 1 '*X 2= 0 ). Інтуїтивно повинно бути зрозуміло, що можна отримати максимальну кількість інформації щодо залежної змінної з експериментальної області (області, визначеної параметрами рівнів факторів), якщо всі ефекти факторів ортогональні один одному. І навпаки, припустімо, що ми провели чотирипрохідний експеримент для двох факторів:
| х 1 | х 2 | |
|---|---|---|
| Біг 1 Біг 2 Біг 3 Біг 4 |
1 1 -1 -1 |
1 1 -1 -1 |
Тепер стовпці налаштувань факторів для X 1 і X 2 ідентичні один одному (їх кореляція дорівнює 1 ), і в результатах неможливо розрізнити основний ефект для X 1 і X 2 .
Процедури D- та A - оптимального проектування надають різні варіанти вибору зі списку дійсних (кандидатів) точок (тобто комбінацій налаштувань факторів) тих точок, які витягнуть максимальну кількість інформації з експериментальної області, враховуючи відповідну модель які ви очікуєте відповідати даним. Вам потрібно надати список точок-кандидатів, наприклад точок вершини та центроїда, обчислених за допомогою опції « Дизайн для обмеженої поверхні та сумішей », вказати тип моделі, яку ви очікуєте підібрати до даних, і кількість прогонів для експерименту. Потім він побудує проект із бажаною кількістю випадків, який забезпечить якомога більшу ортогональність між стовпцями матриці дизайну.
Обґрунтування D- та A - оптимальності обговорюється, наприклад, у Бокса та Дрейпера (1987, Розділ 14). Різні алгоритми, що використовуються для пошуку оптимальних проектів, описані в Dykstra (1971), Galil і Kiefer (1980) і Mitchell (1974a, 1974b). Детальне порівняльне дослідження різних алгоритмів обговорюється в Cook і Nachtsheim (1980).
Основні ідеї
Технічне обговорення міркувань (та обмежень) D- та A - оптимальних проектів виходить за рамки цього вступу. Однак загальні ідеї досить прості. Знову розглянемо простий двофакторний експеримент у чотирьох прогонах.
| х 1 | х 2 | |
|---|---|---|
| Біг 1 Біг 2 Біг 3 Біг 4 |
1 1 -1 -1 |
1 1 -1 -1 |
Як згадувалося вище, цей дизайн, звичайно, не дозволяє перевірити незалежно один від одного статистичну значущість внеску двох змінних у прогнозування залежної змінної. Якщо ви обчислили кореляційну матрицю для двох змінних, вони будуть корелювати на 1 :
| х 1 | х 2 | |
|---|---|---|
| х 1 х 2 |
1,0 1,0 | 1,0 1,0 |
Зазвичай цей експеримент можна провести так, щоб два фактори змінювалися незалежно один від одного:
| х 1 | х 2 | |
|---|---|---|
| Біг 1 Біг 2 Біг 3 Біг 4 |
1 1 -1 -1 |
1 -1 1 -1 |
Тепер ці дві змінні некорельовані, тобто кореляційна матриця для двох факторів є:
| х 1 | х 2 | |
|---|---|---|
| х 1 х 2 |
1,0 0,0 | 0,0 1,0 |
Інший термін, який зазвичай використовується в цьому контексті, полягає в тому, що два фактори є ортогональними. Технічно, якщо сума добутків елементів двох стовпців ( векторів ) у проекті ( матриці проектування ) дорівнює 0 (нулю), то два стовпці є ортогональними.
Визначник матриці проектування. Визначник D квадратної матриці (як кореляційних матриць 2 на 2, наведених вище) — це конкретне числове значення, яке відображає ступінь незалежності або надмірності між стовпцями та рядками матриці. Для випадку 2 на 2 він просто обчислюється як добуток діагональних елементів мінус недіагональні елементи матриці (для великих матриць обчислення складніші). Наприклад, для двох матриць, показаних вище, визначник D є:
| D 1 = |
|1,0 1,0| |1,0 1,0| |
= 1*1 - 1*1 = 0 |
| D 2 = |
|1,0 0,0| |0,0 1,0| |
= 1*1 - 0*0 = 1 |
Таким чином, визначник для першої матриці, обчисленої з повністю надлишкових налаштувань фактора, дорівнює 0 . Визначник для другої матриці, коли множники ортогональні, дорівнює 1 .
D-оптимальні конструкції. Це базове співвідношення поширюється на більші матриці проектування, тобто чим більше надлишкових векторів (стовпців) матриці проектування, тим ближчим до 0 (нулю) є визначник кореляційної матриці для цих векторів; чим більш незалежні стовпці, тим більшим є визначник цієї матриці. Таким чином, знаходження матриці плану, яка максимізує детермінант D цієї матриці, означає знаходження плану, де вплив факторів є максимально незалежним один від одного. Цей критерій вибору конструкції називається критерієм D-оптимальності .
Матричні позначення. Насправді обчислення зазвичай виконуються не на кореляційній матриці векторів, а на простій матриці перехресного добутку. У матричній нотації, якщо матриця дизайну позначена X , то величина, що цікавить тут, є визначником X'X (X - транспонований раз X ). Таким чином, пошук D-оптимальних планів спрямований на максимізацію |X'X|, де вертикальні лінії (|..|) вказують на визначник.
А-оптимальні конструкції. Озираючись назад до обчислень для визначника, інший спосіб поглянути на проблему незалежності — це максимізувати діагональні елементи матриці X'X , мінімізуючи при цьому недіагональні елементи. Так званий критерій сліду або критерій A-оптимальності виражає цю ідею. Технічно А - критерій визначається як:
A = trace(X'X) -1
де trace означає суму діагональних елементів ( матриці (X'X) -1 ).
Інформаційна функція. Тут слід зазначити, що D -оптимальні плани мінімізують очікувану помилку передбачення для залежної змінної, тобто ці плани максимізують точність прогнозу, а отже, інформацію (яка визначається як обернена помилка), що витягується з експериментальної області інтересу.
Вимірювання ефективності дизайну
Для узагальнення ефективності проекту було запропоновано ряд стандартних заходів.
D-ефективність. Ця міра пов’язана з D -критерієм оптимальності:
D-ефективність = 100 * (|X'X| 1/p /N)
Тут p — кількість факторних ефектів у дизайні (стовпці в X ), а N — кількість запитаних прогонів. Цю міру можна інтерпретувати як відносну кількість прогонів (у відсотках), яка потрібна ортогональному плану для досягнення того самого значення визначника |X'X|. Однак пам’ятайте, що ортогональний дизайн у багатьох випадках може бути неможливим, тобто це лише теоретичний «аршин». Таким чином, ви повинні використовувати цей показник радше як відносний показник ефективності, щоб порівняти інші проекти такого ж розміру та створені на основі того самого списку кандидатів на точки проектування. Також зауважте, що цей показник є значущим (і про нього буде повідомлено), лише якщо ви вирішите перекодувати параметри факторів у проекті (тобто налаштування факторів для точок дизайну в списку кандидатів), щоб вони мали мінімум - 1 і максимум +1 .
А-ефективність. Ця міра пов’язана з критерієм A-оптимальності:
A-ефективність = 100 * p/trace(N*(X'X) -1 )
Тут p позначає кількість факторних ефектів у проекті, N — кількість запитаних прогонів, а трасування позначає суму діагональних елементів (з (N*(X'X) -1 ) ). Цю міру можна інтерпретувати як відносну кількість прогонів (у відсотках), яка потрібна ортогональному плану для досягнення того самого значення траси (X'X) -1 . Однак, знову ж таки, ви повинні використовувати цей показник як відносний показник ефективності, щоб порівняти інші проекти такого ж розміру та створені з того самого списку кандидатів на точки проектування; також ця міра має значення, лише якщо ви вирішили перекодувати параметри фактора в проекті від -1 до+1 діапазон.
G-ефективність. Ця міра обчислюється як:
G-ефективність = 100 * квадратний корінь (p/N)/  M
M
Знову ж таки, p означає кількість факторних ефектів у дизайні, а N – кількість запитаних прогонів; M (сигма M ) позначає максимальну стандартну помилку для прогнозу в списку кандидатів. Ця міра пов'язана з так званим G - критерієм оптимальності; G-оптимальні схеми визначаються як такі, що мінімізують максимальне значення стандартної помилки прогнозованої реакції.
Побудова оптимальних проектів
Об’єкти оптимального проектування будуть «шукати» оптимальні проекти, враховуючи список «балів-кандидатів». Іншими словами, маючи список точок, який визначає, які регіони дизайну є дійсними або можливими, і враховуючи вказану користувачем кількість запусків для фінального експерименту, він вибере точки для оптимізації відповідного критерію. Цей «пошук» найкращого дизайну є не точним методом, а скоріше алгоритмічною процедурою, яка використовує певні стратегії пошуку, щоб знайти найкращий дизайн (відповідно до відповідного критерію оптимальності).
Процедури або алгоритми пошуку, які були запропоновані, описані нижче (для огляду та детального порівняння див. Cook and Nachtsheim, 1980). Тут вони розглядаються в порядку швидкості, тобто послідовний метод або метод Dykstra є найшвидшим методом, але часто він, швидше за все, буде невдалим, тобто дасть дизайн, який не є оптимальним (наприклад, лише локально оптимальним; ця проблема буде обговорено незабаром).
Послідовний або метод Дікстри. Цей алгоритм належить Dykstra (1971). Починаючи з порожнього дизайну, він здійснюватиме пошук у списку кандидатів і вибиратиме на кожному кроці той, який максимізує вибраний критерій. Немає жодних ітерацій, вони просто виберуть потрібну кількість точок послідовно. Таким чином, цей спосіб є найшвидшим з розглянутих. Крім того, за замовчуванням цей метод використовується для створення початкових проектів для інших методів.
Метод простого обміну (Вінна-Мітчелла). Цей алгоритм зазвичай приписують Мітчеллу і Міллеру (1970) і Вінну (1972). Метод починається з початкового дизайну запитаного розміру (за замовчуванням створеного за допомогою описаного вище алгоритму послідовного пошуку). У кожній ітерації одна точка (пробіг) у проекті буде видалена з проекту, а інша додана зі списку точок-кандидатів. Вибір точок, які потрібно відкинути або додати, є послідовним, тобто на кожному кроці вибирається точка, яка має найменший внесок щодо вибраного критерію оптимальності ( D або A) виключається з дизайну; потім алгоритм вибирає точку зі списку кандидатів, щоб оптимізувати відповідний критерій. Алгоритм зупиняється, коли додаткові обміни не досягають подальшого покращення.
Алгоритм DETMAX (обмін з екскурсіями). Цей алгоритм, завдяки Мітчеллу (1974b), є, ймовірно, найвідомішим і найбільш широко використовуваним алгоритмом пошуку оптимального дизайну. Подібно до методу простого обміну, спочатку створюється початковий дизайн (за замовчуванням за допомогою описаного вище алгоритму послідовного пошуку). Пошук починається з простого обміну, як описано вище. Однак, якщо відповідний критерій ( D або A ) не покращиться, алгоритм здійснить екскурсії . Зокрема, алгоритм буде додавати або віднімати більше ніж одну точку за раз, так що під час пошуку кількість точок у дизайні може змінюватися між N D + N екскурсією таN D - N excursion , де N D - запитуваний проектний розмір, а N excursion відноситься до максимально допустимого відхилення, як зазначено користувачем. Ітерації припиняться, коли вибраний критерій ( D або A ) більше не покращується в межах максимального відхилення.
Модифікований Федоровим (одночасне перемикання). Цей алгоритм являє собою модифікацію (Cook and Nachtsheim, 1980) основного алгоритму Федорова, описаного нижче. Він також починається з початкового дизайну потрібного розміру (за замовчуванням створеного за допомогою алгоритму послідовного пошуку). У кожній ітерації алгоритм буде обмінюватися кожною точкою в дизайні з одним, вибраним зі списку кандидатів, щоб оптимізувати дизайн відповідно до вибраного критерію ( D або A). На відміну від простого алгоритму обміну, описаного вище, обмін відбувається не послідовно, а одночасно. Таким чином, у кожній ітерації кожна точка в дизайні порівнюється з кожною точкою в списку кандидатів, і обмін здійснюється для пари, яка оптимізує дизайн. Алгоритм припиняє роботу, коли немає подальших покращень у відповідному критерії оптимальності.
Федоров (одночасне перемикання). Це оригінальний метод одночасного перемикання, запропонований Федоровим (див. Cook and Nachtsheim, 1980). Різниця між цією процедурою та описаною вище (з модифікацією Федорова ) полягає в тому, що в кожній ітерації виконується лише один обмін, тобто в кожній ітерації оцінюються всі можливі пари точок у дизайні та в списку кандидатів. Потім алгоритм обміняється парою, яка оптимізує дизайн (щодо вибраного критерію). Таким чином, легко побачити, що цей алгоритм потенційно може бути дещо повільним, оскільки на кожній ітерації виконується N D *N C порівнянь, щоб обміняти одну точку.
Загальні рекомендації
Якщо ви подумаєте про основні стратегії, представлені різними алгоритмами, описаними вище, має бути зрозуміло, що зазвичай не існує точних рішень оптимальної задачі проектування. Зокрема, визначник матриці X'X (і слід її оберненої) є складними функціями списку точок-кандидатів. Зокрема, зазвичай існує декілька «локальних мінімумів» щодо обраного критерію оптимальності; наприклад, у будь-який момент під час пошуку дизайн може здаватися оптимальним, якщо ви одночасно не відкинете половину пунктів у дизайні та не виберете певні інші пункти зі списку кандидатів; але, якщо ви обмінюєте лише окремі бали або лише кілька балів (через DETMAX), покращення не відбувається.
Тому важливо спробувати кілька різних початкових конструкцій і алгоритмів. Якщо після повторення оптимізації кілька разів із випадковими запусками ті самі або дуже подібні остаточні оптимальні результати проектування, тоді ви можете бути достатньо впевнені, що ви не «спіймані» в локальному мінімумі чи максимумі.
Крім того, методи, описані вище, значно відрізняються щодо їх здатності «захоплюватися» в локальних мінімумах або максимумах. За загальним правилом, чим повільніший алгоритм (тобто, чим далі в списку алгоритмів, описаних вище), тим більша ймовірність, що алгоритм дасть справді оптимальний дизайн. Однак зауважте, що модифікований алгоритм Федорова практично працюватиме так само добре, як і немодифікований алгоритм (див. Cook and Nachtsheim, 1980); тому, якщо час не має значення, ми рекомендуємо модифікований алгоритм Федорова як найкращий метод для використання.
D-оптимальність і A-оптимальність. З обчислювальних причин (див. Galil and Kiefer, 1980) оновлення траси матриці (для A -критерію оптимальності) відбувається набагато повільніше, ніж оновлення визначника (для D -оптимальності). Таким чином, коли ви обираєте A -критерій оптимальності, обчислення можуть вимагати значно більше часу порівняно з D -критерієм оптимальності. Оскільки на практиці існує багато інших факторів, які впливатимуть на якість експерименту (наприклад, надійність вимірювання для залежної змінної), ми зазвичай рекомендуємо вам використовувати критерій оптимальності D. Однак у складних ситуаціях проектування, наприклад, коли з’являється багато локальних максимумів дляКритерій D , а повторні випробування дають дуже різні результати, можливо, ви захочете запустити кілька випробувань оптимізації, використовуючи критерій A , щоб дізнатися більше про різні типи можливих дизайнів.
Уникнення сингулярності матриці
Під час процесу пошуку може статися, що він не може обчислити обернену матрицю X'X (для A -оптимальності), або що визначник матриці стає майже нульовим. У цей момент пошук зазвичай не може бути продовжений. Щоб уникнути цієї ситуації, виконайте оптимізацію на основі розширеної матриці X'X :
X'X доповнено = X'X + *(X 0 'X 0 /N 0 )
де X 0 позначає матрицю дизайну, створену зі списку всіх N 0 точок-кандидатів, а ( alpha ) — це визначена користувачем мала константа. Таким чином, ви можете вимкнути цю функцію, встановивши значення 0 (нуль).
«Ремонт» конструкцій
Оптимальні особливості конструкції можна використовувати для «ремонту» конструкцій. Наприклад, припустімо, що ви запустили ортогональний проект, але деякі дані були втрачені (наприклад, через несправність обладнання), і тепер деякі цікаві ефекти більше не можна оцінити. Ви, звичайно, можете надолужити втрачені пробіжки, але припустімо, що у вас немає ресурсів, щоб повторити їх усі. У такому випадку ви можете налаштувати список точок-кандидатів серед усіх дійсних точок для експериментального регіону, додати до цього списку всі точки, які ви вже запустили, і наказати йому завжди вставляти ці точки в остаточний дизайн (і ніколи їх не вилучати, ви можете позначити пункти у списку кандидатів для такого примусового включення). Тоді він розглядатиме лише те, щоб виключити з проекту ті моменти, які ви насправді не запускали. Таким чином ви можете, наприклад,
Обмежені експериментальні області та оптимальний дизайн
Типове застосування оптимальних конструктивних особливостей полягає в ситуаціях, коли експериментальна область інтересу обмежена. Як описано раніше в цьому розділі, існують засоби для пошуку точок вершини та центроїда для лінійно обмежених областей і сумішей. Потім ці точки можна подати як список кандидатів для побудови оптимального дизайну певного розміру для конкретної моделі. Таким чином, ці два засоби разом забезпечують дуже потужний інструмент, щоб впоратися зі складною ситуацією проектування, коли проектна область, що цікавить, підлягає складним обмеженням, і потрібно встановити конкретні моделі з найменшою кількістю прогонів.
| Індексувати |
У наступних розділах представлено кілька методів аналізу. У розділах описується профіль відповіді/бажаності , проведення аналізу залишків і виконання перетворень Бокса-Кокса залежної змінної.
Див. також ANOVA/MANOVA , Методи дисперсійного аналізу та компоненти дисперсії та змішану модель ANOVA/ANCOVA .
Профілювання прогнозованих відповідей і бажаності відповіді
Основна ідея. Типовою проблемою при розробці продукту є пошук набору умов або рівнів вхідних змінних, які створюють найбільш бажаний продукт з точки зору його характеристик або відповідей на вихідні змінні. Процедури, які використовуються для вирішення цієї проблеми, як правило, включають два кроки: (1) прогнозування відповідей на залежні, або змінні Y , шляхом підгонки спостережуваних відповідей за допомогою рівняння на основі рівнів незалежних, або змінних X , і (2) знаходження рівні змінних X , які одночасно виробляють найбільш бажані прогнозовані відповіді на Yзмінні. Derringer і Suich (1980) наводять, як приклад цих процедур, проблему пошуку найбільш бажаної суміші протектора шини. Існує ряд змінних Y , таких як індекс стирання PICO, 200-відсотковий модуль, подовження при розриві та твердість. Характеристики продукту з точки зору змінних відповіді залежать від інгредієнтів, змінних X , таких як рівень гідратованого кремнезему, рівень силанового сполучного агента та сірки. Проблема полягає в тому, щоб вибрати рівні для X, які максимізують бажаність відповідей на Y. Рішення має брати до уваги той факт, що рівні для X, які максимізують одну відповідь, можуть не максимізувати іншу відповідь.
При аналізі схем 2**(kp) (дворівневий факторіал) , 2-рівневих схем скринінгу , 2**(kp) максимально неконфундованих і мінімальних аберацій , 3**(kp) і схем Box Behnken , змішаних 2 і 3 плани рівнів , центральні композиційні дизайни та схеми сумішей . Профілювання відповіді/бажаності дозволяє перевірити поверхню відгуку, отриману підгонкою спостережуваних відповідей за допомогою рівняння на основі рівнів незалежних змінних.
Профілі передбачення. Коли ви аналізуєте результати будь-якого з перерахованих вище планів, окреме рівняння прогнозу для кожної залежної змінної (що містить різні коефіцієнти, але однакові члени) підбирається до спостережуваних відповідей на відповідну залежну змінну. Після того, як ці рівняння сконструйовано, прогнозовані значення для залежних змінних можуть бути обчислені для будь-якої комбінації рівнів предикторних змінних. Профіль прогнозу для залежної змінної складається з ряду графіків, по одному для кожної незалежної змінної, прогнозованих значень для залежної змінної на різних рівнях однієї незалежної змінної, утримуючи рівні інших незалежних змінних постійними на заданих значеннях, які називаються поточні значення . Якщо доречнопоточні значення для незалежних змінних були обрані, перевірка профілю передбачення може показати, які рівні змінних предикторів дають найбільш бажану прогнозовану реакцію на залежну змінну.
Хтось може бути зацікавлений у перевірці прогнозованих значень для залежних змінних лише на фактичних рівнях, на яких незалежні змінні були встановлені під час експерименту. Крім того, можна також зацікавитися перевіркою прогнозованих значень для залежних змінних на рівнях, відмінних від фактичних рівнів незалежних змінних, використаних під час експерименту, щоб побачити, чи можуть існувати проміжні рівні незалежних змінних, які могли б створити навіть більш бажані відповіді. Крім того, повертаючись до прикладу Derringer і Suich (1980), для деяких змінних відповіді найбільш бажані значення можуть не обов’язково бути найбільш екстремальними значеннями, наприклад, найбільш бажане значення подовження може входити до вузького діапазону можливих значень .
Бажаність відповіді.Різні залежні змінні можуть мати різні типи зв’язків між балами змінної та бажаністю балів. Менш насичене пиво може бути більш бажаним, але кращий смак пива також може бути більш бажаним - нижчі оцінки «наповнюваності» та вищі оцінки «смаку» є більш бажаними. Зв'язок між прогнозованими відповідями на залежну змінну та бажаністю відповідей називається функцією бажаності. Derringer і Suich (1980) розробили процедуру визначення зв'язку між прогнозованими відповідями на залежну змінну та бажаністю відповідей, процедуру, яка передбачає до трьох точок "перегину" у функції. Повертаючись до прикладу суміші протектора шини, описаного вище, їхня процедура включала перетворення балів за кожною з чотирьох змінних результатів суміші протектора шини в бали бажаності, які могли коливатися від 0,0 для небажаного до 1,0 для дуже бажаного. Наприклад, їхня бажана функція для твердості суміші протектора шини була визначена шляхом призначення бажаного значення 0,0 показникам твердості нижче 60 або вище 75, бажаного значення 1,0 до середнього показника твердості 67,5, бажаного значення, яке збільшило лінійно від 0,0 до 1,0 для показників твердості від 60 до 67,5 і бажане значення, яке лінійно зменшувалося від 1,0 до 0,0 для показників твердості від 67,5 до 75,0. У більш загальному плані вони припустили, що процедури для визначення функцій бажаності повинні враховувати кривизну у «спаді» бажаності між точками перегину у функціях. 0 для дуже бажаного. Наприклад, їхня бажана функція для твердості суміші протектора шини була визначена шляхом призначення бажаного значення 0,0 показникам твердості нижче 60 або вище 75, бажаного значення 1,0 до середнього показника твердості 67,5, бажаного значення, яке збільшило лінійно від 0,0 до 1,0 для показників твердості від 60 до 67,5 і бажане значення, яке лінійно зменшувалося від 1,0 до 0,0 для показників твердості від 67,5 до 75,0. У більш загальному плані вони припустили, що процедури для визначення функцій бажаності повинні враховувати кривизну у «спаді» бажаності між точками перегину у функціях. 0 для дуже бажаного. Наприклад, їхня бажана функція для твердості суміші протектора шини була визначена шляхом призначення бажаного значення 0,0 показникам твердості нижче 60 або вище 75, бажаного значення 1,0 до середнього показника твердості 67,5, бажаного значення, яке збільшило лінійно від 0,0 до 1,0 для показників твердості від 60 до 67,5 і бажане значення, яке лінійно зменшувалося від 1,0 до 0,0 для показників твердості від 67,5 до 75,0. У більш загальному плані вони припустили, що процедури для визначення функцій бажаності повинні враховувати кривизну у «спаді» бажаності між точками перегину у функціях. від 0 до показників твердості нижче 60 або вище 75, бажане значення від 1,0 до середньої оцінки твердості 67,5, бажане значення, яке лінійно зростає від 0,0 до 1,0 для показників твердості між 60 і 67,5, і бажане значення, яке лінійно зменшується від 1,0 до 0,0 для показників твердості від 67,5 до 75,0. У більш загальному плані вони припустили, що процедури для визначення функцій бажаності повинні враховувати кривизну у «спаді» бажаності між точками перегину у функціях. від 0 до показників твердості нижче 60 або вище 75, бажане значення від 1,0 до середньої оцінки твердості 67,5, бажане значення, яке лінійно зростає від 0,0 до 1,0 для показників твердості між 60 і 67,5, і бажане значення, яке лінійно зменшується від 1,0 до 0,0 для показників твердості від 67,5 до 75,0. У більш загальному плані вони припустили, що процедури для визначення функцій бажаності повинні враховувати кривизну у «спаді» бажаності між точками перегину у функціях.
Після перетворення прогнозованих значень залежних змінних при різних комбінаціях рівнів предикторних змінних в індивідуальні показники бажаності можна обчислити загальну бажаність результатів при різних комбінаціях рівнів предикторних змінних. Derringer і Suich (1980) запропонували обчислювати загальну бажаність як середнє геометричне індивідуальних бажань (що має інтуїтивний сенс, оскільки якщо індивідуальна бажаність будь-якого результату дорівнює 0,0 або неприйнятна, загальна бажаність буде 0,0 або неприйнятна, незалежно від того, наскільки бажаними є інші окремі результати - середнє геометричне бере добуток усіх значень і підносить добуток до степеня, зворотного кількості значень). Derringer and Suich' Процедура забезпечує простий спосіб перетворення прогнозованих значень для кількох залежних змінних у єдину загальну оцінку бажаності. Тоді проблема одночасної оптимізації кількох змінних відповіді зводиться до вибору рівнів змінних предикторів, які максимізують загальну бажаність відповідей на залежні змінні.
Резюме.Коли хтось розробляє продукт, характеристики якого, як відомо, залежать від «інгредієнтів», з яких він складається, виробництво найкращого продукту вимагає визначення впливу інгредієнтів на кожну характеристику продукту, а потім пошуку балансу інгредієнтів, який оптимізує загальну бажаність продукту. З точки зору аналітики даних, процедура, яка дотримується для максимізації бажаності продукту, полягає в тому, щоб (1) знайти адекватні моделі (тобто прогнозні рівняння) для прогнозування характеристик продукту як функції рівнів незалежних змінних і (2) визначити оптимальні рівні незалежних змінних для загальної якості продукту. Ці два кроки, якщо їх точно дотримуватися, швидше за все, приведуть до більшого успіху в удосконаленні продукту, ніж легендарний,
Аналіз залишків
Основна ідея. Розширений аналіз залишків – це набір методів для перевірки різних залишкових і прогнозованих значень і, таким чином, для перевірки адекватності моделі прогнозування, необхідності перетворень змінних у моделі та наявності викидів у даних.
Залишки - це відхилення спостережуваних значень залежної змінної від прогнозованих значень, заданих поточною моделлю. Моделі дисперсійного аналізу, які використовуються для аналізу відповідей залежної змінної, роблять певні припущення щодо розподілу залишкових (але не прогнозованих) значень залежної змінної. Ці припущення можна підсумувати, сказавши, що модель ANOVA передбачає нормальність , лінійність , гетероскедастичність і незалежність залишків. Усі ці властивості залишків для залежної змінної можна перевірити за допомогою аналізу залишків .
Перетворення Бокса-Кокса залежних змінних
Основна ідея. У дисперсійному аналізі передбачається, що дисперсії в різних групах (експериментальні умови) однорідні та не корельовані із середніми значеннями. Якщо розподіл значень у кожній експериментальній умові спотворений, а середні значення корелюють зі стандартними відхиленнями, тоді можна часто застосувати відповідне перетворення ступеня до залежної змінної, щоб стабілізувати дисперсії та зменшити або усунути кореляцію між середніми і стандартні відхилення. Перетворення Бокса-Кокса корисне для вибору відповідного (ступеневого) перетворення залежної змінної.
Вибір опції перетворення Бокса-Кокса створить графік залишкової суми квадратів , заданої моделі, як функцію значення лямбда , де лямбда використовується для визначення перетворення залежної змінної,
| y' = ( y**(лямбда) - 1) / (g**(лямбда-1) * лямбда) | якщо лямбда 0 |
| y' = g * натуральний логарифм (y) | якщо лямбда = 0 |
де g — середнє геометричне залежної змінної, а всі значення залежної змінної є невід’ємними. Значення лямбда , для якого залишкова сума квадратів є мінімальною, є оцінкою максимальної правдоподібності для цього параметра. Він створює дисперсійне перетворення залежної змінної, яке зменшує або усуває кореляцію між груповими середніми значеннями та стандартними відхиленнями.
На практиці не важливо, щоб ви використовували точне оцінене значення лямбда для перетворення залежної змінної. Швидше, як правило, слід розглянути такі перетворення:
| Приблизне лямбда |
Запропонована трансформація y |
|---|---|
| -1 -0,5 0 0,5 1 |
Взаємозворотний Зворотний квадратний корінь Натуральний логарифм Квадратний корінь Немає |
Додаткову інформацію про цю сімейство перетворень див. у Box and Cox (1964), Box and Draper (1987) і Maddala (1977).
| Індексувати |